

飞象网讯(魏德龄/文)近日,MLCommons公布了MLPerf Training v1.0新一轮比赛结果,结果显示英伟达合伙伙伴所提供的各种搭载NVIDIA技术的系统再次取得了出色的成绩。而随着AI领域能力的进一步提升,也为开拓更多领域的应用提供了契机,并助力超级计算无处不在。
全球最快AI模型训练速度
MLPerf 是由学术界、研究实验室和业界人士组成的人工智慧领袖联盟,基于“打造公平、实用基准”的使命,为硬体、软体和服务的训练与推断效能提供中立评估,且全部在预定条件下执行。该基准测试基于当今最常用的AI工作负载和场景,涵盖计算机视觉、自然语言处理、推荐系统、强化学习等。
此前,英伟达生态系统一直在测试中表现出不俗的成绩,例如在2020年7月底公布的第三轮MLPerf榜单中英伟达A100 Tensor Core GPU 在全部八项基准测试中展现了最快性能。在实现总体最快的大规模解决方案方面,利用HDR InfiniBand实现多个DGX A100系统互联的服务器集群DGX SuperPOD系统也同样创造了业内最优性能。
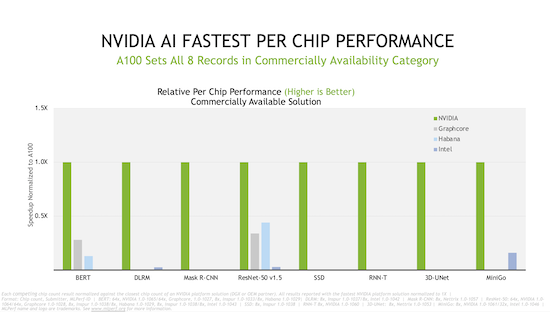
本次MLCommons的新一轮赛事,是英伟达生态系统第四次参加MLPerf训练测试。在芯片对比中,英伟达及其合作伙伴在最新商用解决方案测试的所有八项基准测试中都创造了纪录。
测试中,七家公司对至少十几款市售系统进行了测试,由英伟达AI助力的系统超过了75%,除英伟达外,还包括了戴尔、富士通、技嘉、浪潮、联想、宁畅、超微等。仅有Google、Graphcore、Habana、英特尔、鹏程科技使用其它系统。其中英伟达及合作伙伴或采用了NVIDIA A100 GPU,或计划为在线实例、服务器和PCIe卡采用NVIDIA A100 GPU,以及包括近40款NVIDIA认证系统。
实现这一成绩背后的原因在于,尽管A100 Tensor Core GPU在去年已经雄霸MLPerf测试,英伟达工程师又使其在GPU、系统、网络和AI软件方面继续实现了进步。例如,通过全新的使用CUDA Graphs启动完整神经网络模型的方法,能够解决过去测试中的CPU瓶颈;另在大规模测试中使用的是NVIDIA SHARP,整合网络交换机内的多项通信工作,从而减少网络流量和等待CPU的时间。
助力超级计算无处不在
相较上一轮测试成绩,英伟达将性能整体提升了2.1倍,另通过多次测试结果综合来看,英伟达在两年半的时间内将性能提高了多达6.5倍。性能的快速增长,也为客户在拓展人工智能的全新落地领域提供了更多可能。
此前,在AI应用案例中,棋类的深度学习、图形类别识别、物体重量辨识、物体高度辨识、自然语言处理等已经被广泛应用,测试项中的MiniGo、Mask R-CNN、SSD等也呼应了上述的应用需求。如今在MLPerf测试中加入的RNN-T、3D-UNet测试,也预示着行业对于如语音辨识、生物医学图像方面的全新需求。英伟达及合伙伙伴在八项测试中的创纪录表现,也意味着在实际的人工智能应用中,能够带来更高的效率。
目前,德国癌症研究中心就与英伟达展开合作,将3D-UNet等创新技术引入医疗市场,来实现生物医学图像上的功能。这一合作也证明了MLPerf的测试结果能够给IT机构和开发者以极大的参考,来找到合适的解决方案,以加速特定项目和应用。本次测试中,英伟达AI在3D-UNet上的性能表现甚至是第二名的6倍之多。

人工智能的训练无疑是一项超级计算级别的挑战,而英伟达正在让这一能力变得无处不在。根据全球前500的超级计算机榜单显示,基于NVIDIA DGX SuperPOD的Selene是全球最快的商用AI超级计算机。而榜单上的其他十几台系统也均基于NVIDIA DGX SuperPOD架构。
此外,特斯拉构建的来获得自动驾驶模型的AI超级计算机系统,也选择英伟达的硬件架构作为自动驾驶与辅助驾驶深度学习训练超级电脑AUTOMOTIVE的关键元件。该系统共具备720个节点,每个节点拥有8块NVIDIA A100 Tensor Core GPU,共计5760块。
不久前,微软也宣布由NVIDIA A100 Tensor Core GPU驱动的Azure ND A100 v4云GPU实例全面上市。这些虚拟机(VM)针对的是拥有高性能和高要求工作负载的客户,如人工智能(AI)和机器学习(ML)工作负载。
甚至,英伟达还和美国国家能源研究科学计算中心打造了世界上最快的AI超级计算机,这款名为Perlmutter的超级计算机拥有6144个NVIDIA A100 Tensor Core GPU,从而可以负责拼接有史以来最大的可见宇宙3D地图以及其他项目。以往,研究人员准备一年的星系数据发布需要几周或几个月时间,而通过在英伟达助力下的Perlmutter仅需要几天就能完成任务。




