


首发即支持!昇思MindSpore 0day 支持智谱开源GLM-4-0414全部6个模型
4月15日,昇思MindSpore开源社区、魔乐社区第一时间上架智谱全新开源的GLM-4-0414 32B/9B模型,并完成性能测试。智谱GLM-4-0414拥有 32B/9B两个尺寸,涵盖基座、推理、沉思模型,均遵循 MIT 许可协议。其中,推理模型 GLM-Z1-32B-0414 性能媲美 DeepSeek-R1 等顶尖模型,实测推理速度可达 200 Tokens/秒。
模型介绍:

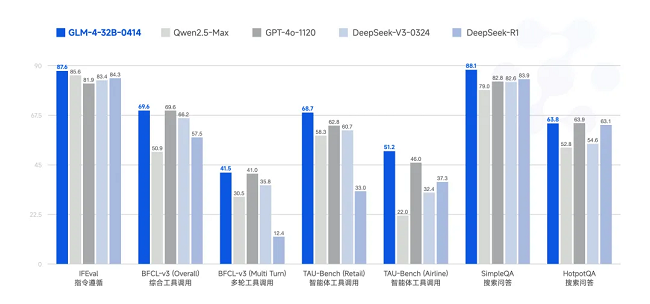
基座模型 GLM-4-32B-0414 拥有 320 亿参数,其性能可与国内、外参数量更大的主流模型相媲美。该模型利用 15T 高质量数据进行预训练,特别纳入了丰富的推理类合成数据,为后续的强化学习扩展奠定了基础。在后训练阶段,除了进行面向对话场景的人类偏好对齐,还通过拒绝采样和强化学习等技术,重点增强了模型在指令遵循、工程代码生成、函数调用等任务上的表现,以强化智能体任务所需的原子能力。
GLM-4-32B-0414 在工程代码、Artifacts 生成、函数调用、搜索问答及报告撰写等任务上均表现出色,部分 Benchmark 指标已接近甚至超越 GPT-4o、DeepSeek-V3-0324(671B)等更大模型的水平。
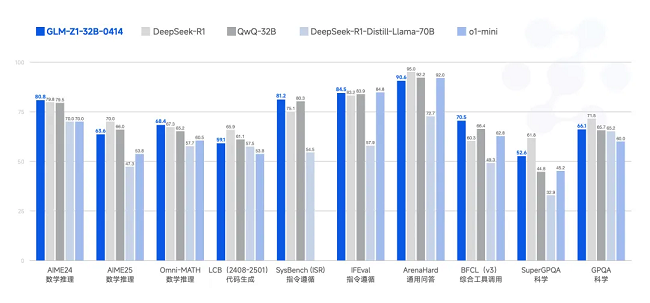
GLM-Z1-32B-0414 是一款具备深度思考能力的推理模型。该模型在 GLM-4-32B-0414 的基础上,采用了冷启动与扩展强化学习策略,并针对数学、代码、逻辑等关键任务进行了深度优化训练。与基础模型相比,GLM-Z1-32B-0414 的数理能力和复杂问题解决能力得到显著增强。此外,训练中整合了基于对战排序反馈的通用强化学习技术,有效提升了模型的通用能力。
在部分任务上,GLM-Z1-32B-0414 凭借 32B 参数,其性能已能与拥有 671B 参数的 DeepSeek-R1 相媲美。通过在 AIME 24/25、LiveCodeBench、GPQA 等基准测试中的评估,GLM-Z1-32B-0414 展现了较强的数理推理能力,能够支持解决更广泛复杂任务。
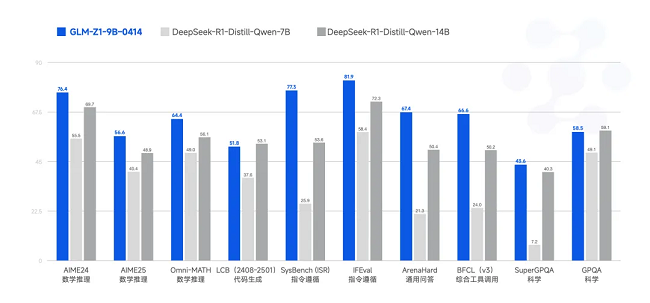
GLM-Z1-9B-0414 是沿用了上述一系列技术,训练出的一个 9B 的小尺寸模型。虽然参数量更少,但GLM-Z1-9B-0414 在数学推理及通用任务上依然表现出色,整体性能已跻身同尺寸开源模型的领先水平。特别是在资源受限的场景下,该模型可以很好地在效率与效果之间取得平衡,为需要轻量化部署的用户提供强有力的选择。
沉思模型GLM-Z1-Rumination-32B-0414 代表了智谱对 AGI 未来形态的下一步探索。与一般推理模型不同,沉思模型通过更多步骤的深度思考来解决高度开放与复杂的问题。其关键创新在于,它能在深度思考过程中整合搜索工具处理复杂任务,并运用多种规则型奖励机制来指导和扩展端到端的强化学习训练。该模型支持“自主提出问题—搜索信息—构建分析—完成任务”的完整研究闭环,从而在研究型写作和复杂检索任务上的能力得到了显著提升。
欢迎广大开发者下载体验!
魔乐社区下载链接:
https://modelers.cn/models/MindSpore-Lab/GLM-4-32B-Base-0414https://modelers.cn/models/MindSpore-Lab/GLM-Z1-Rumination-32B-0414https://modelers.cn/models/MindSpore-Lab/GLM-Z1-32B-0414https://modelers.cn/models/MindSpore-Lab/GLM-Z1-9B-0414https://modelers.cn/models/MindSpore-Lab/GLM-4-32B-0414https://modelers.cn/models/MindSpore-Lab/GLM-4-9B-0414
以下为手把手教程:
(以GLM-Z1-9B-0414+昇思MindSpore基于昇腾推理为例)
# 01
快速开始
GLM-Z1-9B-0414推理至少需要1台(1卡)Atlas 800T A2(64G)服务器(基于BF16权重)。昇思MindSpore提供了GLM-Z1-9B-0414推理可用的Docker容器镜像,供开发者快速体验。
1、下载昇思 MindSpore 推理容器镜像
执行以下 Shell 命令,拉取昇思 MindSpore GLM-Z1 推理容器镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindspore_glm_z1:20250414
1、启动容器
docker run -it --privileged --name=GLM-Z1 --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
swr.cn-central-221.ovaijisuan.com/mindformers/mindspore_glm_z1:20250414
/bin/bash
注意事项:
● 如果部署在多机上,每台机器中容器的hostname不能重复。如果有部分宿主机的hostname是一致的,需要在起容器的时候修改容器的hostname。
● 后续所有操作均在容器内操作。
2、模型下载
执行以下命令为自定义下载路径 /home/work/GLM-Z1-9B-0414 添加白名单:
export HUB_WHITE_LIST_PATHS=/home/work/GLM-Z1-9B-0414
执行以下 Python 脚本从魔乐社区下载昇思 MindSpore 版本的 GLM-Z1-9B-0414 文件至指定路径 /home/work/GLM-Z1-9B-0414 。下载的文件包含模型代码、权重、分词模型和示例代码,占用约18GB 的磁盘空间:
from openmind_hub import snapshot_download
snapshot_download(
repo_,
local_dir="/home/work/GLM-Z1-9B-0414",
local_dir_use_symlink=False
)
下载完成的 /home/work/GLM-Z1-9B-0414 文件夹目录结构如下:
GLM-Z1-9B-0414
├── config.json # 模型json配置文件
├── tokenizer.model # 词表model文件
├── tokenizer_config.json # 词表配置文件
├── predict_glm4_z1_9b.yaml # 模型yaml配置文件
└── weights
├── model-xxxxx-of-xxxxx.safetensors # 模型权重文件
├── tokenizer.json # 模型词表文件
├── xxxxx # 若干其他文件
└── model.safetensors.index.json # 模型权重映射文件
注意事项:
● /home/work/GLM-Z1-9B-0414 可修改为自定义路径,确保该路径有足够的磁盘空间(约 18GB)。
● 下载时间可能因网络环境而异,建议在稳定的网络环境下操作。
# 02
服务化部署
1、修改模型配置文件
在 predict_glm_z1_9b.yaml 中对以下配置进行修改(若为默认路径则无需修改):
load_checkpoint: '/home/work/GLM-Z1-9B-0414/weights' # 配置为实际的模型绝对路径
auto_trans_ckpt: True # 打开权重自动切分,自动将权重转换为分布式任务所需的形式
load_ckpt_format: 'safetensors'
processor:
tokenizer:
vocab_file: "/home/work/GLM-Z1-9B-0414/tokenizer.model" # 配置为tokenizer文件的绝对路径
2、一键启动MindIE
MindSpore Transformers提供了一键拉起MindIE脚本,脚本中已预置环境变量设置和服务化配置,仅需输入模型文件目录后即可快速拉起服务。进入 mindformers/scripts 目录下,执行MindIE启动脚本
cd /home/work/mindformers/scripts
bash run_mindie.sh --model-name GLM-Z1-9B-0414 --model-path /home/work/GLM-Z1-9B-0414 --max-prefill-batch-size 1
参数说明:
● --model-name:设置模型名称
● --model-path:设置模型目录路径
查看日志:
tail -f output.log
当log日志中出现 `Daemon start success!` ,表示服务启动成功。
3、执行推理请求测试
执行以下命令发送流式推理请求进行测试:
curl -w "\ntime_total=%{time_total}\n" -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"inputs": "请介绍一个北京的景点", "parameters": {"do_sample": false, "max_new_tokens": 128}, "stream": false}' http://127.0.0.1:1025/generate_stream &```
# 03
声明
本文档提供的模型代码、权重文件和部署镜像,当前仅限于基于昇思MindSpore AI框架体验GLM-Z1-9B-0414 的部署效果,不支持生产环境部署。
相关使用问题请反馈至ISSUE(链接:https://gitee.com/mindspore/mindformers/issues)。
昇思MindSpore AI框架将持续支持相关主流模型演进,并根据开源情况面向全体开发者提供镜像与支持。
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
5G-A赋能机器人火炬接力:中国移动以技术革新点亮全运科技盛宴
2025年11月,第十五届全国运动会将在粤港澳三地盛大启幕。这场赛事不仅是体育健儿的竞技场,更是前沿科技落地应用的“试验田”。其中,11月2日的机器人火炬接力作为本次全运会的核心创新亮点..[详细]
轻薄机型出师未捷身先死,长使业绩泪满襟
当iPhone Air宣布上市当天,随着各路评测内容解禁,一个显眼的标题也随之出现,那就是“注定停产”。轻薄机型的出现一方面让人们看到厂商正在挖掘全新市场空间,另一方面也勾起了小尺寸机型..[详细]
智能未来:宇宙为你闪烁
未来十年,你家的电表可能再也不用换电池,自动驾驶汽车能"看到"几公里外的路况,甚至海洋深处的传感器都能实时传回数据。这些不是科幻,而是刚刚在无锡物博会上发布的《2025全球..[详细]
智能IP广域网成为筑牢智算产业发展根基的关键一环
随着国家加速推动智算产业高质量发展,网络支撑能力已成为产业进阶的核心抓手,而作为关键基础设施的智能IP广域网,正凭借其在算力调度、数据传输中的核心作用,成为筑牢智算产业发展根基的..[详细]
大中华区市场失守 苹果寄望AI驱动未来增长
苹果公司公布的2025 财年第四季度财报呈现“冰火两重天”态势:全球营收1024.66亿美元同比增长 8%,净利润274.66亿美元同比激增86.4%,毛利率攀升至 47.18%。但作为第三大市场的大中华区却成..[详细]









