


3节点集群带宽突破 513GBps 焱融存储再度登顶MLPerf Storage 全球榜单
2025 年 8 月 4 日,全球权威的 AI 性能基准评测组织 MLCommons® 正式发布最新一轮 MLPerf® Storage v2.0 基准测试结果。来自中国的存储厂商焱融科技在此次测试中表现突出,其全闪存储一体机 F9000X 不仅在全部模型测试中性能领先,更以三节点存储集群 513GB/s 的总带宽刷新 3D-Unet 模型测试的纪录,登顶 MLPerf 全球性能榜单。
MLPerf Storage:AI 存储性能的黄金衡量标准
MLCommons 作为全球人工智能工程联盟,始终致力于规范 AI 技术的准确性、安全性、速度与效率评估,推动 AI 系统性能优化,其权威性得到全球业界广泛认可。而 MLPerf Storage Benchmark 作为该联盟专为 AI 场景打造的存储基准测试,通过模拟真实 AI 训练中的 I/O 操作,精准衡量存储系统向 GPU 输送训练数据的速度与能力。
此次发布的 MLPerf Storage v2.0,在 v1.0 基础上进一步升级:除保留 3D-Unet、ResNet50、CosmoFlow 三大训练模型外,新增 Checkpoint 工作负载,更全面覆盖训练中断点恢复、模型存档等实际场景。为确保结果的严谨性与公正性,v2.0 要求每项基准测试必须多次重复执行(训练任务 5 次、Checkpoint 任务 10 次),且全程连续运行无失败,同步提交完整测试日志,最终结果取多次运行的平均值 ―― 这一系列严格规范,使其成为业界衡量 AI 存储性能时最具参考价值的权威标准。
焱融全闪刷新全球纪录 最小规模集群性能第一
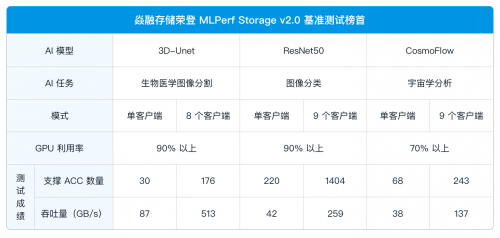
MLPerf Storage 基准测试既支持单个计算节点(客户端)运行多个 ACC(GPU 加速器)的模型测试,也适配分布式训练集群场景 ―― 通过多客户端模拟真实数据并行访问存储集群,充分覆盖从单节点到分布式集群的全场景 AI 工作负载。其最关键的衡量标准,是在保证高性能 GPU 利用率(3D-Unet 与 ResNet50 模型下为 90%,CosmoFlow 模型下为 70%)的前提下,存储系统所能实现的聚合带宽。这项指标是衡量存储系统实际能力的核心,直接体现其在 AI 训练过程中是否能够充分“喂饱”计算资源,避免造成 GPU 空闲浪费。
最新测试结果显示,在 3D-Unet、ResNet50 以及 CosmoFlow 所有模型的测试场景下,于通用硬件环境中,针对分布式存储的最小规模集群,即三节点存储集群,焱融全闪 F9000X 在全球知名分布式存储厂商中脱颖而出,集群总带宽等关键指标位列全球第一。尤其是在 3D-Unet 模型测试中,集群带宽达到 513 GB/s ,为迄今已公布结果中的最高值。
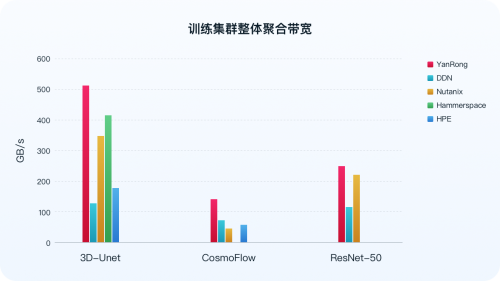
数据来源:MLCommns 官方 https://mlcommons.org/benchmarks/storage/
除分布式场景外,在单客户端测试中,焱融全闪 F9000X 同样展现出优异性能,进一步验证了其在不同部署规模下的强劲数据处理能力。
此外,在新增的 Checkpoint 工作负载测试中,针对 Llama3-70B 模型场景,通过部署 8 个客户端模拟并发请求、搭配 64 个模拟 GPU 环境,实现 221 GB/s 读取带宽与 79 GB/s 写入带宽的高性能表现。这种稳定且高效的带宽支撑能力,能够精准保障 Checkpoint 文件在模型训练全流程中实现秒级极速读写,从底层存储层面为 AI 训练任务的断点续训连续性与模型训练稳定性筑牢技术根基,助力企业从容应对大规模模型训练的严苛存储需求。
焱融存储 MLPerf 测试表现背后:技术积淀与生态协同是关键
据了解,焱融存储去年便参与了 MLPerf Storage v1.0 基准测试,并以出色成绩从全球知名存储厂商中强势突围。焱融存储之所以能在 MLPerf 存储基准测试中持续取得优异成绩,核心在于其长期深耕 AI 大模型训练与推理等核心场景的技术积累:一方面,通过长期深耕大模型训练与推理等核心场景,深度理解 AI 工作负载特性;另一方面,从架构设计到软硬件全技术栈,持续推进系统性创新与优化,构建起应对高性能负载的核心能力。
与此同时,焱融也与 NVIDIA、Intel、新华三(H3C)、忆恒创源(Memblaze)、大普微(DapuStor)等上下游生态伙伴展开深度协同,在网络、芯片、服务器、SSD 等关键环节紧密合作,实现软硬件的深度适配与极致优化,有效保障系统在 AI 基础设施全链路中的高效稳定运行。
公开资料显示,焱融全闪存储基于其自研的高性能分布式文件系统 YRCloudFile,通过多项关键技术实现性能突破:
采用自研 Multi-Channel 网络带宽聚合技术,可整合多张 InfiniBand/RoCE 网卡性能,在大 IO 场景下充分释放硬件潜力,支撑超高速数据传输;
系统具备负载感知能力,可根据压力智能切换中断与轮询模式,有效提升 IOPS 性能;
在 IO 模型层面,通过异步非阻塞设计减少上下文切换、增强并行处理能力,并通过处理器核心资源的高效分配,降低线程调度开销,支撑高并发数据处理的同时,充分发挥 NVMe SSD 的性能优势;
针对大规模 GPU 集群易出现的网络拥塞问题,专项优化传输机制,保障数据传输的高效与稳定。
随着大模型向千亿、万亿参数演进,存储作为底层支撑的性能要求持续提升。此次焱融科技在 MLPerf Storage v2.0 中的表现,不仅印证了中国存储厂商的技术实力,也为 AI 基础设施的性能优化提供了可参考的实践路径。业内预计,未来存储系统的高带宽、低延迟能力依然是 AI 大模型广泛落地的关键竞争力之一。
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
5G-A赋能机器人火炬接力:中国移动以技术革新点亮全运科技盛宴
2025年11月,第十五届全国运动会将在粤港澳三地盛大启幕。这场赛事不仅是体育健儿的竞技场,更是前沿科技落地应用的“试验田”。其中,11月2日的机器人火炬接力作为本次全运会的核心创新亮点..[详细]
轻薄机型出师未捷身先死,长使业绩泪满襟
当iPhone Air宣布上市当天,随着各路评测内容解禁,一个显眼的标题也随之出现,那就是“注定停产”。轻薄机型的出现一方面让人们看到厂商正在挖掘全新市场空间,另一方面也勾起了小尺寸机型..[详细]
智能未来:宇宙为你闪烁
未来十年,你家的电表可能再也不用换电池,自动驾驶汽车能"看到"几公里外的路况,甚至海洋深处的传感器都能实时传回数据。这些不是科幻,而是刚刚在无锡物博会上发布的《2025全球..[详细]
智能IP广域网成为筑牢智算产业发展根基的关键一环
随着国家加速推动智算产业高质量发展,网络支撑能力已成为产业进阶的核心抓手,而作为关键基础设施的智能IP广域网,正凭借其在算力调度、数据传输中的核心作用,成为筑牢智算产业发展根基的..[详细]
大中华区市场失守 苹果寄望AI驱动未来增长
苹果公司公布的2025 财年第四季度财报呈现“冰火两重天”态势:全球营收1024.66亿美元同比增长 8%,净利润274.66亿美元同比激增86.4%,毛利率攀升至 47.18%。但作为第三大市场的大中华区却成..[详细]









