

ЙПәЈИЛ№ӨЦЗДЬКөСйКТБӘәПЗе»ӘҙуС§ЎўТБАыЕөТБҙуС§ПгйД·ЦРЈөИС§ё®Ј¬ЧйҪЁ№ъјКНЕ¶УСР·ўРВ·Ҫ·ЁЈ¬НЁ№э Clip-Cov әН KL-Cov јјКхУРР§УҰ¶ФІЯВФмШұААЈОКМвЎЈ
ұіҫ°јтҪй
ҙуРНУпСФДЈРНЈЁLLMsЈ©ҪьДкАҙФЪНЖАнДЬБҰЙПөДН»ЖЖЈ¬ИГЗҝ»ҜС§П°ЈЁRLЈ©өДУҰУГ·¶О§ҙУөҘТ»ИООсА©Х№өҪёь№г·әөДіЎҫ°Ј¬ХвЦЦҪшІҪёіУиБЛДЈРНёьЗҝөД·ә»ҜДЬБҰәНВЯјӯНЖАнДЬБҰЎЈ
И»¶шЈ¬Улҙ«НіөДДЈ·ВС§П°І»Н¬Ј¬Зҝ»ҜС§П°РиТӘёьёЯөДјЖЛгЧКФҙАҙЦ§іЦҙУҫӯСйЦРС§П°Ј¬әЛРДОКМвФЪУЪІЯВФмШЈЁ·ҙУіБЛДЈРНФЪАыУГТСЦӘІЯВФәНМҪЛчРВІЯВФЦ®јдөДЖҪәвЈ©өДПВҪөЎЈ
мШЦө№эөН»бөјЦВДЈРН№э¶ИТААөТСУРІЯВФЈ¬ЙҘК§МҪЛчДЬБҰЎЈХвТ»МҪЛч-АыУГИЁәвЈЁexploitation-exploration trade-offЈ©КЗЗҝ»ҜС§П°өД»щҙЎЈ¬ИзәОҝШЦЖІЯВФмШіЙОӘСөБ·ЦРөД№ШјьДСМвЎЈ
ІЯВФмШұААЈөДАнВЫУлКөјщН»ЖЖ
ОӘҪвҫцХвТ»ОКМвЈ¬СРҫҝНЕ¶УМбіцБЛТ»ёцҫӯС鹫КҪЈәR = a exp H + bЈ¬ЖдЦР H ҙъұнІЯВФмШЈ¬R ОӘПВУОИООсұнПЦЈ¬a әН b ОӘДвәППөКэЎЈХвТ»№«КҪҪТКҫБЛІЯВФРФДЬУлмШЦөЦ®јдөДИЁәв№ШПөЈ¬ЦёіцмШәДҫЎКЗРФДЬЖҝҫұЎЈ
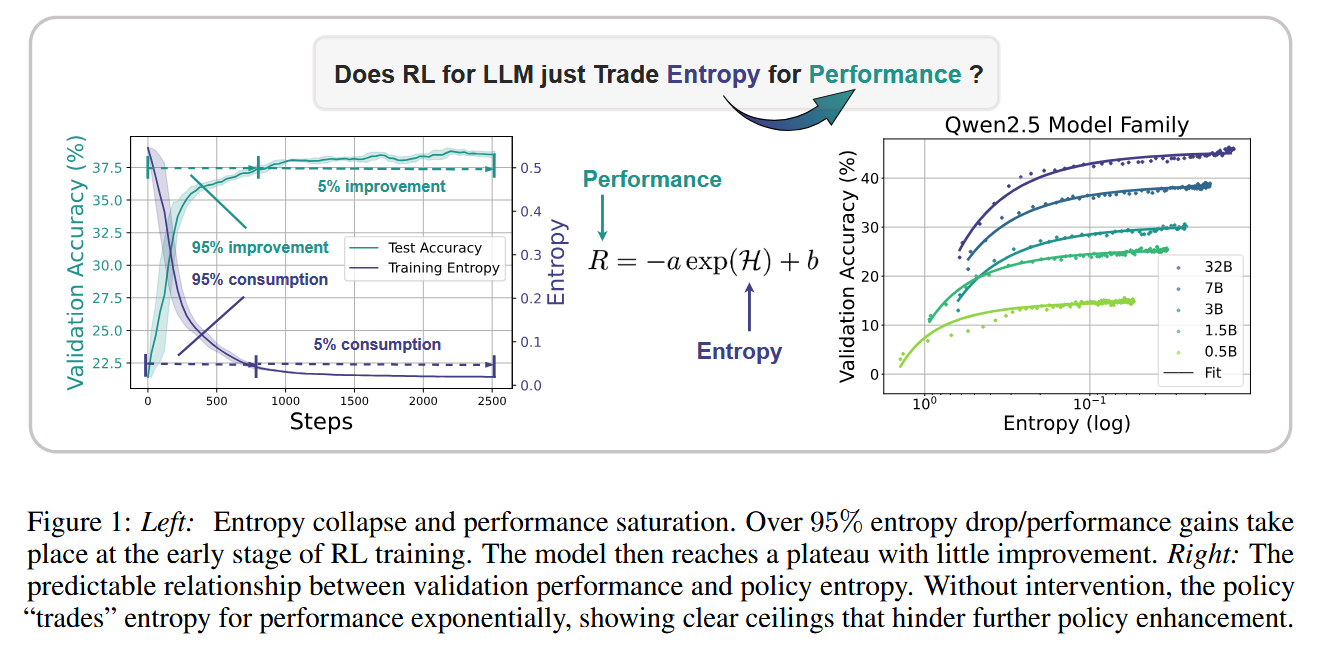
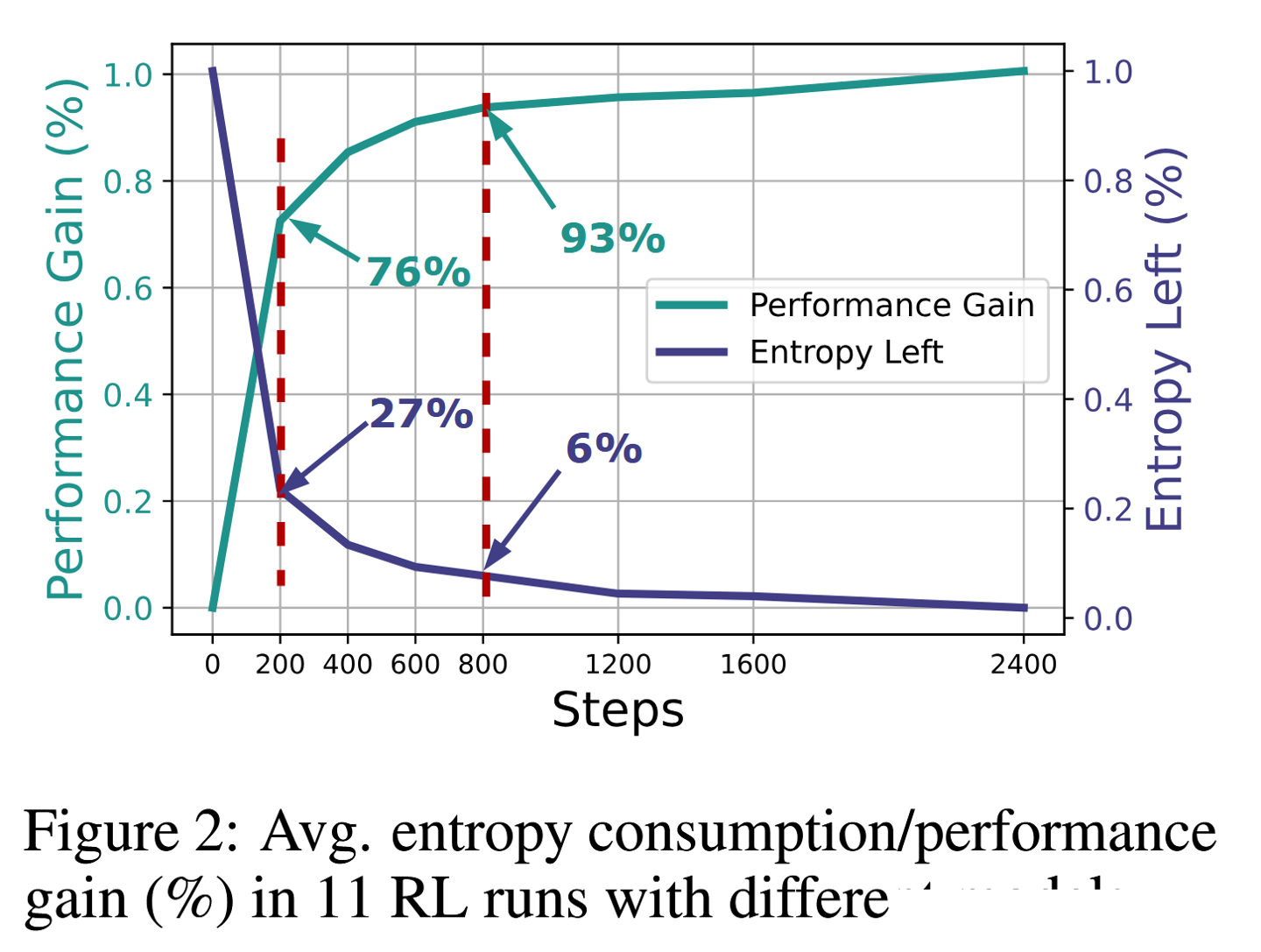
СРҫҝҪшТ»ІҪ·ЦОцБЛмШ¶ҜМ¬ұд»ҜЈ¬·ўПЦЖдКЬ¶ҜЧчёЕВКУл logits ұд»ҜРӯ·ҪІоөДЗэ¶ҜЎЈОӘҙЛЈ¬НЕ¶УҙҙРВРФөШМбіцБЛ Clip-Cov әН KL-Cov БҪЦЦјјКхЈ¬·ЦұрНЁ№эІГјфёЯРӯ·ҪІо token әНК©јУ KL іН·ЈАҙО¬іЦмШЛ®ЖҪЎЈ
КөСй»щУЪ Qwen2.5 ДЈРНәН DAPOMATH КэҫЭјҜЈ¬ёІёЗКэС§ИООсЈ¬Ҫб№ыПФКҫРВ·Ҫ·ЁФЪ 7B әН 32B ДЈРНЙП·ЦұрМбЙэБЛ 2.0% әН 6.4% өДРФДЬЈ¬УИЖдФЪ AIME24 әН AIME25 өИёЯДС¶И»щЧјІвКФЦРЈ¬32B ДЈРНРФДЬМбЙэёЯҙп 15.0%ЎЈ
СРҫҝНЕ¶УФЪ°ьАЁ Qwen2.5ЎўMistralЎўLLaMA әН DeepSeek ФЪДЪөД 11 ёцҝӘФҙДЈРНЙПҪшРРБЛІвКФЈ¬ІОКэ№жДЈҙУ 0.5B өҪ 32B І»өИЈ¬әӯёЗКэС§әНұаіМИООсөД 8 ёц№«ҝӘ»щЧјІвКФЎЈ
СөБ·ІЙУГ veRL ҝтјЬәНБгСщұҫЙиЦГЈ¬ҪбәП GRPOЎўREINFORCE++ өИЛг·ЁУЕ»ҜІЯВФРФДЬЎЈҪб№ыұнГчЈ¬Clip-Cov әН KL-Cov јјКхДЬО¬іЦёьёЯөДмШЛ®ЖҪЈ¬АэИз KL-Cov ·Ҫ·ЁФЪ»щПЯмШЦөЗчУЪЖҪОИКұИФұЈіЦ 10 ұ¶ТФЙПөДмШЦөЎЈ
ХвІ»ҪцҪвҫцБЛІЯВФмШұААЈОКМвЈ¬ТІОӘЗҝ»ҜС§П°ФЪУпСФДЈРНЦРөДА©Х№МṩБЛАнВЫЦ§іЦЎЈСРҫҝЗҝөчЈ¬мШ¶ҜМ¬КЗРФДЬМбЙэөД№ШјьЖҝҫұЈ¬ОҙАҙРиҪшТ»ІҪМҪЛчмШ№ЬАнІЯВФЈ¬ТФНЖ¶ҜёьЦЗДЬУпСФДЈРНөД·ўХ№ЎЈ








