


高考数学全卷重赛!一道题难倒所有大模型,新选手Gemini夺冠,豆包DeepSeek并列第二
AI挑战全套高考数学题来了!
话接上回。高考数学一结束,我们连夜使用六款大模型产品,按照一般用户截图提问的方式,挑战了 14 道最新高考客观题,不过有网友质疑测评过程不够严谨,所以这次我们加上解答题,重新测一遍。
本次参加挑战的选手分别是:Doubao-1.5-thinking-vision-pro、DeepSeek R1、Qwen3-235b、hunyuan-t1-latest、文心 X1 Turbo、o3,并且新增网友们非常期待的 Gemini 2.5 pro。上一次我们使用网页端测试,这次除 o3 外,其他模型全部调用 API。
在考题选择上,我们仍然采用 2025 年数学新课标 Ⅰ 卷,包含 14 道客观题,总计 73 分;5 道解答题,总计 77 分。其中第 6 题由于涉及到图片,我们就单独摘出来,后面通过上传题目截图的形式针对多模态大模型进行评测。其他文本题目全部转成 latex 格式,分别投喂给大模型,还是老规矩,不做 System Prompt 引导,不开启联网搜索,直接输出结果。
(注:第 17 题虽然也涉及到图片,但文字表述足够清晰,不影响答题,因此也以 latex 格式测评。)
客观题计分方法按照以往高考判分原则:
单选题每道 5 分,选项正确计分,错误不得分;
多选题每道 6 分,全对计 6 分,漏选按正确答案数量计分,如答案为 ABCD,漏选其一扣 1.5 分,错选不得分;
填空题每道 5 分,填空正确计分,错误不得分。
至于解答题,由于现在还未出具体的评分细则,所以我们请数学专业的朋友进行评判,主要还是看大模型的最终答案以及解题步骤中是否有严重失误点。
7 家大模型考试成绩如下图所示。
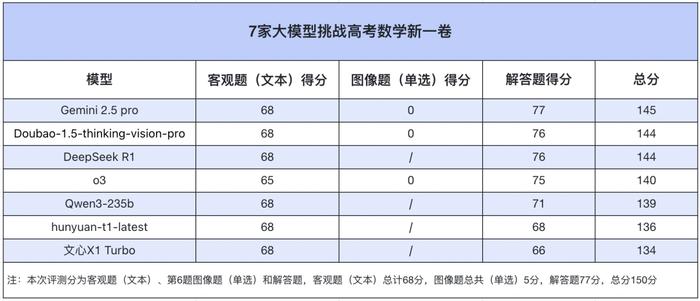
从客观题来看,各家大模型几乎拉不开差距,最大分差也只有 3 分,第 6 题图像题更是让这几家多模态大模型「全军覆没」。在上一次测评中,o3 客观题成绩垫底,但有网友表示,这可能是由于某些原因导致后台自动切换成其他模型,而这一次我们选用的是未「降智」的 o3,选择题和填空题成绩仍是排在最后,当然,65 分的成绩相比「降智」版确实有很大提升。
解答题是大模型失分的「重灾区」。除了 Gemini 2.5 Pro 拿到全部的分数外,其它模型或多或少均有失分。其中 DeepSeek R1 和 Doubao 最可惜,只丢了一分;o3 则失了 2 分,最终得到 75 分。相较而言,hunyuan-t1-latest 和文心 X1 Turbo 发挥不佳,分别拿到 68 分和 66 分。
从总分上来看,Gemini 2.5 Pro 考了 145 分,位列第一,Doubao 和 DeepSeek R1 以 144 分紧随其后,并列第二;o3 和 Qwen3 也仅有一分之差,分别排在第三和第四。受解答题的「拖累」,hunyuan-t1-latest 和文心 X1 Turbo 的总成绩排到了最后两名。
(查看各大模型的测评截图以及解答题答题情况,请移步:https://jiqizhixin.feishu.cn/docx/PR0PdzYaWoU92QxiJQqc2oe7n2g)
解答题:大模型失分「重灾区」
我们先来看看解答题的情况。
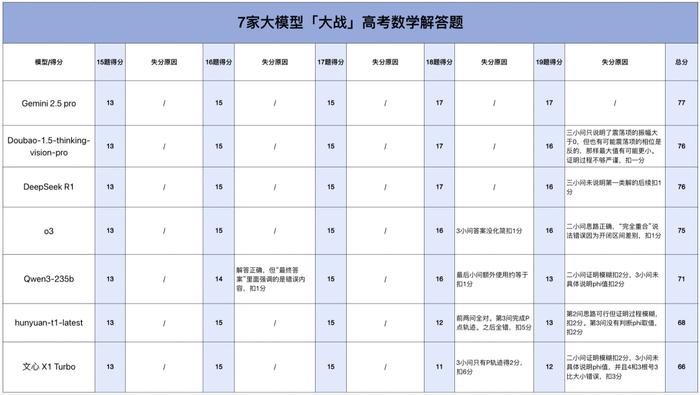
第 15 题和第 17 题,一道考查概率问题,一道涉及立体几何知识,7 家大模型均拿到满分。
第 16 题是一道数列综合题,满分 15 分,只要证明完整、计算过程完整、结果正确就能拿到全部的分数。大模型整体表现不错,只有 Qwen3 解答正确,但最终答案里面增加了多余的假设求值,扣了一分。

第 18 题这道椭圆方程与几何就难倒了不少大模型,仅 Doubao、DeepSeek R1 和 Gemini2.5 Pro 拿到满分 17 分,其他模型各有各的扣分点。Qwen3 前面回答得都不错,过程也很完整,但偏偏最后一小问|PQ|最大值取约等于 9 的步骤多余,导致结果偏差,扣了一分。

o3 则是第(3)问答案没化简丢了一分。

文心 X1 在第 2 问 (2) 正确算出 P 点轨迹,但未证明极值,直接按最远点计算造成结果错误,扣 6 分。

hunyuan-t1-latest 前两问中回答正确,到了第 3 问完成 P 点轨迹之后就全错了,一下子丢了 5 分。

对于最后一道压轴题,Gemini2.5 pro 是唯一全对的大模型。Doubao 只说明了震荡项的振幅大于 0,但是也有可能震荡项的相位是反的,那样的话最大值反而有可能更小,证明过程不够严谨,扣一分。

DeepSeek R1 在第(3)问中分情况讨论,得出了两类解,但对第一类解未做后续说明,扣了一分。

o3 第(2)问思路正确,但因为开闭区间差别,「完全重合」说法错误,扣 1 分。

hunyuan-t1-latest 在第(2)问上思路可行但证明过程模糊,扣 2 分,到了第(3)问没有判断 phi 取值,又扣了 2 分。

文心 X1 和 Qwen3 也都是在第 2 问和第 3 问上失了分,第 2 问证明模糊扣 2 分,第 3 问则是未具体说明 phi 值扣 2 分,而且文心 X1 比大小还发生错误,又扣了 1 分。


客观题:一道图像题难倒几家多模态大模型
在不考虑识图题(第6题)的情况下,客观题大模型总体表现都不错,Doubao、Qwen3、Gemini 2.5 pro、DeepSeek R1 、文心 X1 Turbo 和 hunyuan-t1-latest 均取得了 68 分的高分,只有 o3 在多选题上少选了一项丢了分。
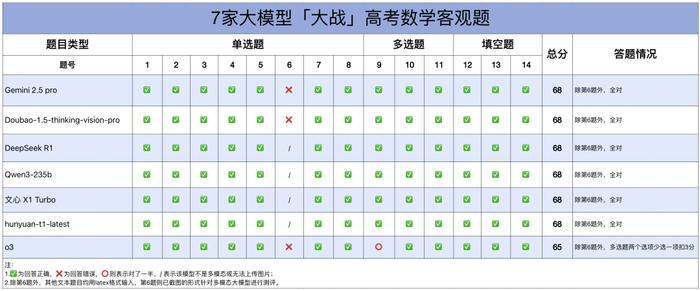
其中,o3 在第 9 题计算过程中,忽视了「正三棱柱」这一关键条件。它在建立坐标系时,分别用 (x₀, y₀, 0) 表示 A 点坐标,用 (c, 0, 0) 表示 C 点坐标,但没有考虑到:正三棱柱的底面是正三角形,这意味着正三角形的边长 c 与 x₀、y₀之间存在关系:c=2x₀=2y₀/√3。导致对 B 选项的判断出现错误。

接下来看看这道图片题。

遗憾的是,此次测评的多模态大模型都在这道识图题上表现不佳。虽然 hunyuan-t1-latest 不是多模态,但我们又测试了 hunyuan-t1-vision ,也在这道题上败下阵来。

相比之下,Doubao 和 o3 至少正确识别了坐标位置,只是误判了视风风速方向,而 Gemini 连基本坐标都未能正确识别。



总的来说,这次测评结果显示,大模型在数学推理能力上有不小的进步,但仍有较大的提升空间。比如不少模型在解答题上丢分,这反映出大模型在复杂推理、严谨论证和多步骤计算方面还需加强。
此外,所有参测的多模态大模型在第 6 题的图像识别上都出现了问题,这也暴露出当前 AI 在图文结合理解方面的短板。
最后,紧张的高考已经结束,祝福所有考生都能取得理想的成绩,有着灿烂的未来!
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
5G-A赋能机器人火炬接力:中国移动以技术革新点亮全运科技盛宴
2025年11月,第十五届全国运动会将在粤港澳三地盛大启幕。这场赛事不仅是体育健儿的竞技场,更是前沿科技落地应用的“试验田”。其中,11月2日的机器人火炬接力作为本次全运会的核心创新亮点..[详细]
轻薄机型出师未捷身先死,长使业绩泪满襟
当iPhone Air宣布上市当天,随着各路评测内容解禁,一个显眼的标题也随之出现,那就是“注定停产”。轻薄机型的出现一方面让人们看到厂商正在挖掘全新市场空间,另一方面也勾起了小尺寸机型..[详细]
智能未来:宇宙为你闪烁
未来十年,你家的电表可能再也不用换电池,自动驾驶汽车能"看到"几公里外的路况,甚至海洋深处的传感器都能实时传回数据。这些不是科幻,而是刚刚在无锡物博会上发布的《2025全球..[详细]
智能IP广域网成为筑牢智算产业发展根基的关键一环
随着国家加速推动智算产业高质量发展,网络支撑能力已成为产业进阶的核心抓手,而作为关键基础设施的智能IP广域网,正凭借其在算力调度、数据传输中的核心作用,成为筑牢智算产业发展根基的..[详细]
大中华区市场失守 苹果寄望AI驱动未来增长
苹果公司公布的2025 财年第四季度财报呈现“冰火两重天”态势:全球营收1024.66亿美元同比增长 8%,净利润274.66亿美元同比激增86.4%,毛利率攀升至 47.18%。但作为第三大市场的大中华区却成..[详细]









