


Soul App发布开源模型SoulX-LiveAct:高鲁棒实时交互数字人,双卡低成本流式生成
近日,Soul App AI团队(Soul AI Lab)发布开源模型SoulX-LiveAct。作为新的实时数字人生成方案,SoulX-LiveAct通过 Neighbor Forcing(同扩散步对齐的自回归条件传播)与 ConvKV Memory(KV 记忆压缩),让 AR diffusion 从“能流式”走向“可真正长时稳定地实时流式”。
现阶段,伴随着AI技术在数字人直播、视频播客、实时互动等场景快速普及,行业应用层对模型的实际需求正在从“能生成”走向“能长期稳定生成”。但在真实落地场景里,数字人生成一直面临一个难题:视频生成一旦拉长到分钟甚至小时级,画面稳定性与一致性会明显下降――常见问题包括身份漂移、细节丢失、画面闪烁,以及实时推理成本随时长上升等。
如何让数字人视频在流式实时推理下做到小时级甚至无限长度、同时保持身份一致/细节稳定/口型精准?
此次开源的SoulX-LiveAct能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。通过不断开源不同技术路线的模型,Soul AI团队为开源社区及行业提供了差异化的实时数字人方案,覆盖各种硬件条件、不同应用落地的开发者实际需求。
・Project Page: https://soul-ailab.github.io/soulx-liveact/
・Technical Report: https://arxiv.org/abs/2603.11746
・Source Code: https://github.com/Soul-AILab/SoulX-LiveAct
・Hugging Face: https://huggingface.co/Soul-AILab/LiveAct
SoulX-LiveAct 三大亮点
1) 恒定显存:真正支持无限时长生成
过去的 AR diffusion 往往依赖 KV cache 记忆历史信息,但缓存会随视频长度线性增长――视频一长,不是爆显存,就是不得不丢历史,稳定性随之崩掉。SoulX-LiveAct 从“条件传播方式”和“历史记忆管理”两个层面解决了这一瓶颈,创新机制使系统既能“带得动”长时历史,又不会因缓存膨胀而拖慢推理,从而在机制上具备小时级甚至更长时长的持续生成能力。
2) 实时吞吐:2 张 H100/H200 即可 20 FPS 流式推理
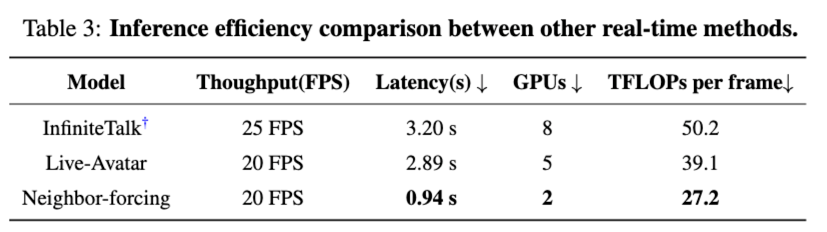
在 512×512 分辨率下,SoulX-LiveAct 仅需 2 张 H100/H200 即可达到 20 FPS 的实时流式推理能力,端到端延迟约 0.94s。同时,单帧计算成本降低到 27.2 TFLOPs / frame,在追求实时的条件下显著减轻算力压力,为线上部署提供更现实的成本方案。
3) 长时一致:身份稳定 + 细节不“掉件”
长视频最容易“翻车”的不是第一分钟,而是第十分钟、第三十分钟:常见现象包括脸漂、发型/衣纹漂移、饰品忽隐忽现,甚至口型逐步失配。在报告的长时对比中,基线方法普遍出现不同程度的身份漂移与细节不稳定;而 SoulX-LiveAct 能在更长时间窗口内保持身份一致性与关键细节持续稳定(如配饰与衣物纹理不“掉件”)。
原理介绍:
SoulX-LiveAct 面向小时级实时数字人动画的流式生成,整体采用 AR Diffusion(自回归扩散)范式,并围绕“长时一致 + 恒定显存”构建两条核心机制:Neighbor Forcing 与 ConvKV Memory。
・AR Diffusion 主干:按 chunk/帧块自回归生成,每个 chunk 内采用扩散建模细节,chunk 间通过条件上下文承接运动与身份信息,实现流式推理闭环。
・Neighbor Forcing(邻近强制):在自回归链上,不传播“不同扩散步”的状态,而是传播 同扩散步 ttt 下的相邻帧 latent 作为条件,使上下文与当前预测处于同一噪声语义空间(step-aligned),显著降低训练/推理中的分布不一致。
・ConvKV Memory(卷积式 KV 记忆):将历史 attention KV 记忆从“线性增长的 cache”改为“短期精确 + 长期压缩”的组合:
近期 KV 保留高精度窗口(保证局部一致与细节稳定)
远期 KV 通过轻量 1D conv 按固定压缩比滚动压缩(例如报告示例 λ=5),把历史信息压缩进固定长度表示,从而实现常量显存推理。
・RoPE Reset(位置对齐):配合 ConvKV Memory 的“压缩+滑动窗口”,通过 RoPE reset 做位置编码对齐,避免长序列位置漂移,强化长时稳定。
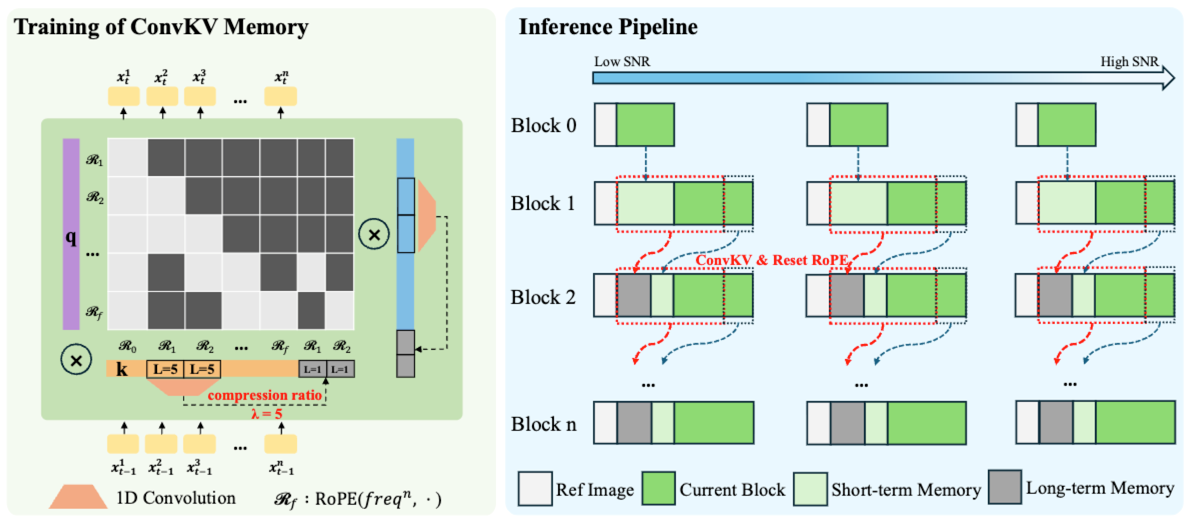
LiveAct 推理时序 + Memory 结构示意图
SoulX-LiveAct 的训练目标不是只追求视频质量,而是显式对齐流式推理的长时误差传播,使模型在“越长越不稳”的场景下仍能保持身份与细节稳定。
・Neighbor Forcing 对齐训练分布:训练时强制模型在同扩散步语境下接收来自“相邻帧”的条件 latent,减少 AR 链中跨步噪声空间不一致带来的优化震荡,使模型更好学到稳定的时序承接规则。
・长时一致性导向的自回归训练构造:训练样本按 chunk 方式组织,显式覆盖“连续 chunk 合成 → 误差累积 → 再纠正”的过程,让模型在训练期就暴露并学习处理长时漂移问题,而不是仅在短 clip 上拟合。
・Memory-Aware 训练(与推理一致):训练阶段引入与推理一致的 ConvKV Memory 使用方式(短期窗口 + 长期压缩),让模型学会在“被压缩的历史记忆”条件下保持身份与细节一致性,避免训练/推理不一致导致的掉点。
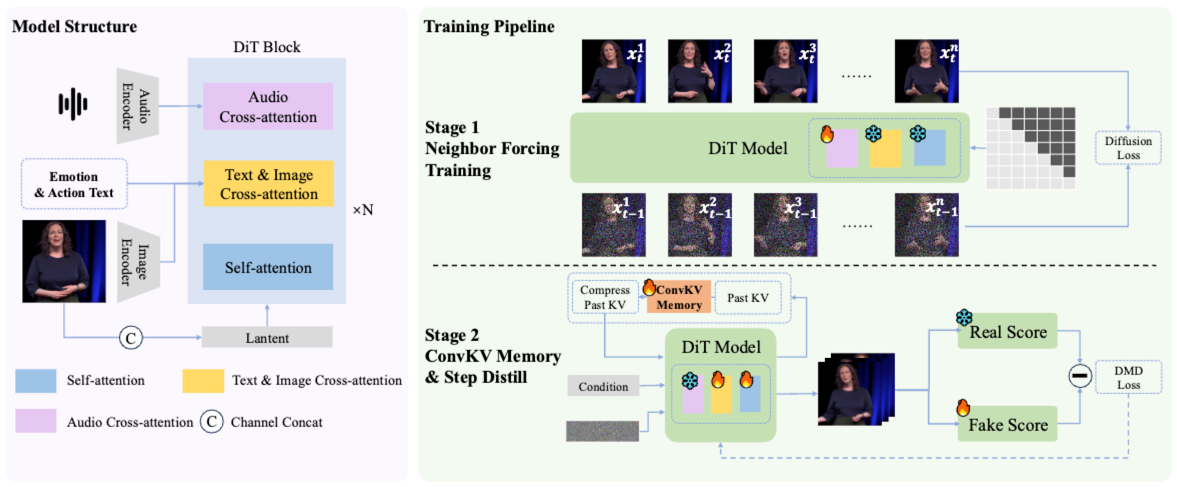
SoulX-LiveAct 的加速思路强调“延迟稳定”而不是“越跑越慢”:核心是把长时上下文从可变 cache 变成可控 memory,从而让实时流式推理不随时长恶化。
・恒定显存(Constant-Memory Inference):ConvKV Memory 把历史 KV 从线性增长变为固定预算,推理显存随视频时长保持恒定,这是小时级在线生成的必要条件。
・稳定延迟(Stable Latency):短期窗口 KV 保证局部质量,长期压缩 KV 保证全局一致;两者组合使每个 chunk 的计算与通信成本保持稳定,不会因为视频越长而拖慢。
・端到端实时能力:在 512×512 下,系统可在 2×H100/H200 条件下实现 20 FPS 的流式推理,并给出约 0.94s 的端到端延迟与 27.2 TFLOPs/frame 的成本口径。
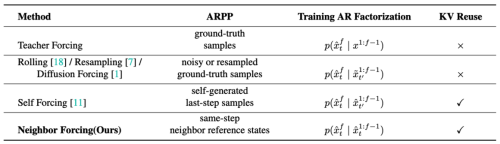
综合表现领先
真正的“长时稳定+实时可用”
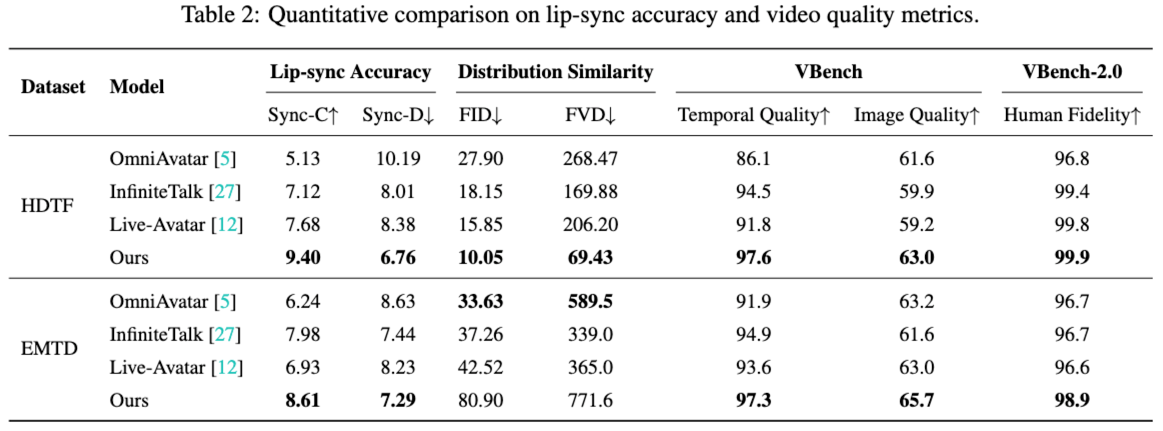
通过在 HDTF(面部口型与真实感)与 EMTD(包含全身动作)两类基准上的定量对比,SoulX-LiveAct 展示了其在 口型同步、动画质量与实时效率上的综合领先:在 HDTF 上,SoulX-LiveAct 取得 9.40 的 Sync-C 与 6.76 的 Sync-D,同时在分布相似性指标上达到 10.05 FID / 69.43 FVD,并在 VBench 上获得 97.6 的 Temporal Quality 与 63.0 的 Image Quality,VBench-2.0 的 Human Fidelity 达到 99.9,体现出更稳定的时序质量与更强的人体与身份一致性;在 EMTD 上,SoulX-LiveAct 依然保持最优同步表现(8.61 Sync-C / 7.29 Sync-D),并在 VBench 上达到 97.3 Temporal Quality / 65.7 Image Quality,Human Fidelity 达到 98.9,证明其对全身动作与复杂表情/动作场景的鲁棒性。
依托模型表现,SoulX-LiveAct 将能够在“长期在线”数字人直播间、AI教育、智慧柜员、知识付费、播客录制、开放世界互动等方向快速落地,例如,在线开放世界的NPC互动中,要求“说得像、动得像、一直像”,SoulX-LiveAct 在全身数据集 EMTD 上的同步与质量指标领先,并支持实时流式推理,适合在数字空间里实现长时间在线的、具备情绪动作表达的角色交互。
今年,在实时数字人生成方向,Soul AI 团队已陆续开源了SoulX-FlashTalk、SoulX-FlashHead,前者是首个能够实现0.87s亚秒级超低延时、32fps高帧率,并支持超长视频稳定生成的14B数字人模型;后者是1.3B轻量化模型,可实现在单张消费级显卡( RTX 4090 )上跑出96FPS的工业级速度。
除了实时数字人生成方向的SoulX-FlashTalk、SoulX-FlashHead、SoulX-LiveAct ,现阶段,Soul AI团队还开源了播客语音合成模型SoulX-Podcast、歌声合成模型 SoulX-Singer、全双工语音对话控制模块SoulX-Duplug,综合来看,团队围绕“实时交互”这一核心领域,在多模态方向不断夯实技术基建,同时通过工程化部署方案将技术推向可真正工业级应用阶段。
而坚持开源方向,Soul不仅完成了自身AI基础设施的持续升级,还通过携手全球开发者,持续拓展“AI+”的新落地场景,共同推动AI应用生态的建设。
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
2026十大科技趋势
2026 十大科技趋势,定义新一年的每一次突破。祝大家马年大吉,马到成功!初八启新程,万事皆顺遂!
[详细]
黄仁勋:需要更多Token与工程师,这是AI革命的开工典礼
3月17日,在美国加州圣何塞开幕的GTC 2026大会上,英伟达创始人兼CEO黄仁勋开始了备受瞩目的主题演讲。来看他演讲的观众需要排队,现场人山人海。这场演讲不仅有黄仁勋对过去二十年技术积累..[详细]
我国算力规模与质量协同跃升,行业赋能效益加速释放
当前,以大模型为代表的人工智能应用驱动全球计算技术进入新一轮创新爆发期,先进计算硬件、软件、算法之间深度融合、协同演进,量子计算、类脑计算等前沿计算架构加快突破,算力需求呈现指..[详细]
如何推进算电协同,筑牢绿色高效硬底座?
随着AI浪潮的快速发展推进,全社会对算力的需求持续扩大,今年的《政府工作报告》也重点提出,要深化拓展“人工智能+”,实施超大规模智算集群、算电协同等新基建工程。在AI算力需求井喷的..[详细]
平时不戴眼镜的高通卡图赞,谈可穿戴设备杀手级AI应用
“我本人不戴眼镜,只在户外戴太阳镜。所以对我来说,可能挂坠或项链这类形态会更舒服,我可以戴在胸前,随时都能完成视觉交互。”卡图赞随后又以个人视角表..[详细]
聚焦两会|以AI赋能新质生产力,人工智能的责任是为人民服务
在“十五五”规划开局的2026年,人工智能作为科技创新与新质生产力的关键支撑,被全民热议、全社会所关注,并在两会上被提升至战略高度。委员代表们集体围绕AI治理、产业创新、民生应用、人..[详细]
MWC2026 爆火关键词:U6GHz 到底是什么?一文看懂
近日巴塞罗那MWC2026大会火热召开,全球最新的ICT科技集体亮相,令人目不暇接。各大厂商在介绍新技术、新产品时,不约而同地强调了对AI的支持能力和价值。[详细]
聚焦两会|具身智能落地场景全面扩容,产业堵点待打通
2026年开年,具身智能成为科技与产业领域的高频热词。从央视春晚舞台上人机共武,到 MWC2026 巴塞罗那展上中国机器人企业集体亮相的全球秀场,舞台与展会的高光背后,是国产具身智能从技术演..[详细]
我国系统推进自动驾驶政策法规体系建设,加速产业发展
近日,中国信息通信研究院(简称“中国信通院”)政策与经济研究所、人工智能与经济社会研究中心联合发布《自动驾驶战略与政策观察(2025年)――推动自动驾驶全场景落地,抢占科技发展制高..[详细]
专题|2026世界移动通信大会
2026年3月2日至5日,世界移动通信大会(MWC)在西班牙巴塞罗那Fira Gran Via会展中心拉开帷幕。本届展会以“The IQ Era”(众智启新)为主题,向世界展示AI与通信深度融合的无限可能。..[详细]









