


阿里发布Qwen3.5-Omni,多模态能力超越Gemini-3.1 Pro
3月31日上午消息,阿里发布千问新一代全模态大模型Qwen3.5-Omni,宣布在音视频理解、识别、交互等215项任务中取得SOTA(性能最佳),超越Gemini-3.1 Pro,成为目前全球最强的全模态大模型之一。
据悉,该模型拥有极强的音视频理解与实时交互能力,能够对音视频内容生成详细且可控的结构化描述,可识别语言和方言数量多达113种,还涌现出了音视频Vibe Coding能力,用户对着镜头阐述需求,就能让模型自主生成App、网页、游戏等复杂产品代码。目前,阿里云百炼已上新Qwen3.5-Omni的Plus、Flash、Light三种API,可广泛应用于短视频/直播平台、游戏、自媒体等行业。
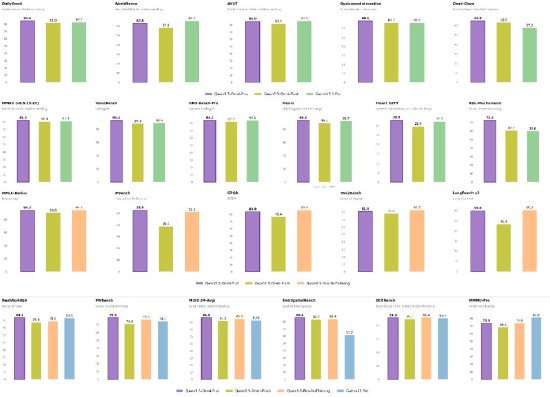
Qwen3.5-Omni采用混合注意力MoE架构,在海量文本、视觉以及超过1亿小时的音视频数据上进行了原生多模态预训练,可实现图片、视频、语音、文字等全模态内容的输入与输出。新模型在音视频理解、跨模态推理、Agent方面实现了性能飞跃,在音视频理解、语音识别、多语种翻译、对话等215项第三方性能测试任务中取得SOTA。
例如,在聚焦视听交互能力的DailyOmni、QualcommInteractive、Omni Cloze等测试中,Qwen3.5-Omni得分领先Gemini-3.1 Pro;在检测嘈杂环境抗干扰能力的WenetSpeech测试中,Qwen3.5-Omni错误率远低于Gemini,识别准确率极高;在考察多语言语音生成质量的Multi-Lingual (30lang) 测试中,Qwen3.5-Omni同样显著优于Gemini-2.5-Pro-TTS。
此外,与纯文本或图片驱动的Vibe Coding不同,千问还可以实现音视频编程:打开摄像头,用户对着草图口述需求,哪怕是包括复杂产品逻辑的描述,模型也能直接生成带有复杂UI的产品原型界面,真正实现“动动嘴即可编程”。这一能力并非刻意设计,而是模型在原生多模态能力持续扩展过程中自然涌现出的结果。
目前,普通用户也可前往Qwen Chat免费体验,开发者和企业可通过阿里云百炼平台调用Qwen3.5-Omni模型,每百万Tokens输入不到0.8元,比Gemini-3.1 Pro的1/10还低。
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
2026十大科技趋势
2026 十大科技趋势,定义新一年的每一次突破。祝大家马年大吉,马到成功!初八启新程,万事皆顺遂!
[详细]
三大运营商2025年报:营收稳中有进 算力等新兴产业成效显现
近日,中国移动、中国电信、中国联通三大电信运营商2025年年度报告已全部对外披露。作为我国数字经济发展的“国家队”与主力军,三大运营商在2025年顶住行业竞争加剧、传统业务增长趋缓等多..[详细]
告别“大黑屏” 智能手机如何走出增长困局?
从首款智能手机问世至今十余年间,这块握在掌心的 “大黑屏” 曾凭借不断刷新的硬件参数掀起一轮轮换机潮,成为移动互联网时代的核心载体。但如今,全球手机市场早已告别高速增长,换机周期..[详细]
中国电信2025年财报透视:双轮融合发力 “AI+”重构增长逻辑
2025 年,中国电信紧扣数字经济与人工智能发展浪潮,完成云改数转向云改数转智惠的战略升级,全年经营业绩稳健收官,核心业务稳固、创新业务高增、数字基建持续加码,在算力、AI、量子、低空..[详细]
当速率不再是核心主题,5G网络好坏如何重新考量?
回首5G网络部署之初,宣传口径往往聚焦于“速率”,但历经时间的反复押韵,很多受众都发现,原来“看电视”这项用例,可以从3G一直宣传到5G。而当如今人们在谈论6G的时候,终于不用再看到满..[详细]
刘烈宏:以高质量数据赋能AI创新,加快培育智能经济新形态
当前,人工智能发展正经历着一场前所未有的加速演进,一个又一个热点事件接连涌现。在技术创新与商业应用的双轮驱动下,人工智能产业规模持续增长,从去年春节DeepSeek开源模型出圈,到机器..[详细]
AI赋能中小企业仍处于初期探索阶段
新一代人工智能正在全球范围蓬勃兴起,成为新一轮科技革命和产业变革的战略性技术和重要驱动力量。开展人工智能赋能中小企业高质量发展研究,既是人工智能技术推进规模化商业化应用、加速向..[详细]
华为启动“乾坤 ・ 众智同行”计划:与伙伴共同创造、共同受益,把中国方案带向世界
AI大潮汹涌而来,千行百业都在向云端、向智能化迁移,期待新的ICT技术方案能够带来更高的工作效率、更好的服务品质、更理想的用户体验。不过每个行业的应用场景不同,每个企业的服务对象和市..[详细]
5G-A大上行成产业共识,差异化体验赋能行业升级
数据显示,截止2026年1月,全球已有374个运营商部署5G网络,为各国用户提供了更好的体验,也涌现了很多新的需求,比如高清直播需要大上行,人群密集场所需要大容量,工业智能化需要低时延等..[详细]
6G时代的智能设备:反思自身、协同彼此、共同推理
经历了MWC26,很多人都对6G有了更加直观的认识,如同5G时代的高速率、低时延、广连接,6G给出的答案是连接、广域感知和高性能计算。不过,正如5G当初所畅想的智能工厂与万物互联,6G自然也需..[详细]









