


NVIDIA RTX PC 与 DGX Spark 加速由 Hermes 解锁的自主进化 AI 智能体
副标题:Hermes: 可靠、可自主进化,并由最新代理式大语言模型驱动,为 NVIDIA RTX PC 与工作站带来全新一代智能体。
作者:Abhishek Gore
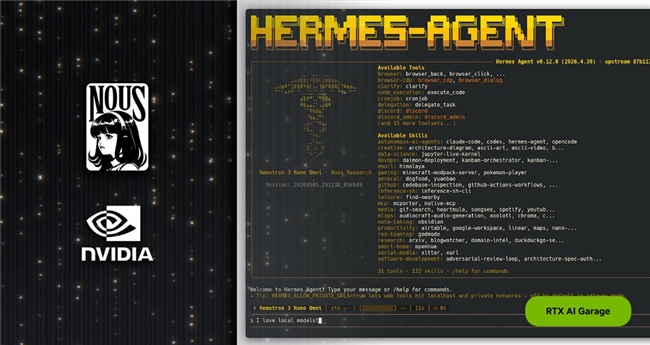
代理式 AI 正在改变用户完成工作的方式。继 OpenClaw 取得成功之后,社区正积极拥抱新的开源代理式框架。最新框架是 Hermes Agent,在不到 3 个月内突破 140,000 GitHub 星标。截至上周,根据 OpenRouter 的数据,它已成为全球使用量最高的智能体。
Nous Research 开发的 Hermes 专为可靠性与自我改进而设计,这两项特质一直以来都很难在智能体中实现。Hermes 特意不绑定提供商和模型,并针对始终在线的本地使用场景进行优化,因此 NVIDIA RTX PC、NVIDIA RTX PRO 工作站和 NVIDIA DGX Spark 成为全天候全速运行它的理想硬件。
Qwen 3.6 是阿里巴巴推出的新一代高性能开放权重大语言模型(LLM)系列,非常适合运行 Hermes 这样的本地智能体。Qwen 3.6 27B 和 35B 参数模型的表现超过了上一代 120B 和 400B 参数模型,并可在 NVIDIA RTX 与 DGX Spark 上运行,为代理式 AI 提供加速。
Hermes:加速本地 AI 智能体能力
与其他热门智能体一样,Hermes 可集成消息应用,访问本地文件和应用,并全天候 24 小时运行。但以下 4 项突出能力让它脱颖而出:
● 自主进化技能:Hermes 会编写并改进自己的技能。每当智能体遇到复杂任务或收到反馈时,它都会将学习成果保存为技能,从而随着时间推移持续适应和改进。
● 受控子智能体:Hermes 将子智能体视为面向子任务的,生命周期很短的单独工作单元,并为其配备专用的上下文和工具集。这可以让任务组织更清晰,减少智能体混淆,并让 Hermes 以更小的上下文窗口运行,非常适合本地模型。
● 可靠性源于设计:Nous Research 会整理并压力测试 Hermes 随附的每一项技能、工具和插件。即使搭配 30B 参数级别的本地模型,Hermes 也能开箱即用,无需像大多数其他智能体框架那样持续调试。
● 同一模型,更好结果:开发者在不同框架中使用相同模型进行比较时,Hermes 始终展现出更好的结果。差异来自框架本身:Hermes 是一个主动编排层,而不是轻量封装器,可支持持久运行的本地端侧智能体,而非逐项任务执行。
Hermes 智能体和底层 LLM 都为本地运行而构建,这意味着硬件质量将直接决定用户体验质量。NVIDIA RTX GPU 正是为这类工作负载而打造。
Qwen 3.6:在本地提供数据中心级智能
最新 Qwen 3.6 模型基于广受认可的 Qwen 3.5 系列打造,为本地 AI 智能体带来又一次飞跃。全新 Qwen 3.6 35B 模型可在约 20GB 内存上运行,同时生成结果超越需要 70GB 以上内存的 120B 参数模型。
Qwen 3.6 27B 是一款新的稠密模型,拥有更多活跃参数,在仅为 Qwen 3.5 397B 等 400B 参数模型 1/16 大小的同时,达到相似的准确率。高端 RTX GPU 可为该模型提供实现高速体验所需的计算能力。
这些模型非常适合 Hermes 这样的本地智能体,而 NVIDIA GPU 和 DGX Spark 是运行它们的最快方式。NVIDIA Tensor Cores 可加速 AI 推理,带来更高吞吐量和更低延迟,让 Hermes 能够在数秒而非数分钟内完成多步骤任务,或改进自身的一项技能。
DGX Spark:始终在线的代理式计算机
Hermes 这样的智能体专为持续运行而构建,可以响应请求、规划多步骤任务、自主执行并自我改进。NVIDIA DGX Spark 是理想搭档,它是一台紧凑、高效的独立设备,专为持续全天候代理式工作流而打造。
128GB 统一内存和 1 petaFLOP AI 性能让 NVIDIA DGX Spark 可全天运行 120B 参数混合专家模型。而全新 Qwen 3.6 35B 模型以更精简的占用空间提供同等智能,不仅运行速度更快,还让用户有能力运行并发工作负载。
要最大限度提升性能并简化使用体验,请阅读 Hermes DGX Spark Playbook。欢迎注册 NVIDIA“Build It Yourself”代理式 AI 系列即将举办的实践课程,了解如何使用 NemoClaw 和 OpenShell 构建自主 AI 智能体。
NVIDIA DGX Spark 现已可通过 NVIDIA 制造合作伙伴订购,相关信息请查看市场页面。
开始在 NVIDIA 硬件上使用 Hermes
在 NVIDIA 硬件上本地运行 Hermes 非常简单。
访问 Hermes GitHub 代码库即可开始使用并将其与用户偏好的本地模型和运行时搭配,并通过 llama.cpp、LM Studio 或 Ollama 运行 Qwen 3.6 以搭配 Hermes。Hermes Agent 原生支持 LM Studio 和 Ollama,为本地智能体提供最简单的上手路径。
无论是探索个人智能体前沿的本地 AI 爱好者,还是为自身工作流构建本地工具的开发者,NVIDIA 硬件上的 Hermes 都能提供独特强大且可靠的基础。
敬请关注 RTX AI Garage,了解针对 NVIDIA RTX 硬件优化的最新开放模型和智能体的更多更新。
#别错过:NVIDIA RTX AI Garage 最新动态
NVIDIA RTX PRO GPU 在运行 Qwen 3.6 模型与 llama.cpp 时,可实现最高 3 倍更快的 token 生成速度。它可为本地 AI 提供所需的实时响应能力,让智能体处理多步骤任务并改进自身技能,从而保持工作流顺畅无缝。
Google Gemma 4 26B 和 31B 模型现已推出 NVFP4 checkpoint,可在 NVIDIA Blackwell GPU 上实现更快性能。将 NVFP4 checkpoint与 Google 全新 Multi-Token Prediction 草稿模型搭配使用,可在相同输出质量下实现最高 3 倍更快推理,让前沿级推理能够在 NVIDIA GPU 上本地运行。
Mistral Medium 3.5 版已于 4月发布,包含与 llama.cpp 和 Ollama 的兼容性更新,使用户能够在 NVIDIA RTX PRO 和 DGX Spark 系统上运行。
NVIDIA 最近推出了 NVIDIA NemoClaw,这是一个可通过增强安全性和支持本地模型的开源堆栈,在 NVIDIA 设备上优化 OpenClaw 体验。NemoClaw 现已支持 Windows Subsystem for Linux(WSL2),为微软平台上的爱好者和开发者带来支持。开始在 DGX Spark 上使用 NemoClaw,请查看 Playbook。
NVIDIA RTX AI PC 的相关信息请关注微博、抖音及哔哩哔哩官方账号。
软件产品信息请查看声明。
关于NVIDIA
NVIDIA (NASDAQ: NVDA) 是加速计算领域的全球领导者。
# # #
媒体咨询:
Jade Li
NVIDIA GeForce, AI PC, DGX Spark PR
邮箱:jadli@nvidia.com
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
AI告别免费?C端大模型变现各有其招
近日,字节跳动旗下AI应用“豆包”宣布推出付费订阅服务。从免费到付费,先圈地后变现,“熟悉的配方,熟悉的味道”,互联网“养肥”再收割的剧本,要在AI赛道重新上演?[详细]
时代变了,“大上行”成为通信网络升级聚焦点
去年开始,无论是展望6G,还是5G-A升级,提升上行能力成为聚焦点之一。然而,过往这并非一个被很多人所关注的速度表现,相比于5G时代超快的下行速率表现,上行速度明显逊色不少。
不过,..[详细]商业、能源、技术三重发力,重塑中国算力网底层运行规则
中国算力网的风向,在金鸡湖畔开幕的这届大会上定下了基调。作为中国移动年度规格最高、战略信号最明确的科技盛会,2026移动云大会于5月8日在苏州盛大开幕,来自国家数据局、中国移动、鹏城..[详细]
工业AI融合困境重重,如何破局?
推进新型工业化,是我国建设制造强国的核心路径,而人工智能作为新一轮科技革命的核心技术,正成为制造业高端化、智能化、绿色化转型的关键引擎。当下,我国制造业与AI融合已从单点技术试点..[详细]
下好AI时代一盘大棋:中国移动如何打造“智能新空间”
随着AI能力持续迭代、应用可靠性稳步提升,AI 智能体加速向千行百业渗透,深度融入大众生产生活,智能时代已在眼前。在AI大潮中,中国移动又将如何拥抱新[详细]
铸信致远 自立自强:中国信科凝聚品牌力量,点亮通信未来
作为信息通信领域中央企业国家队,中国信科立足创新引领、国之重器、匠心坚守核心品牌精神,以科技自立自强为根本遵循,深耕光通信、6G、卫星互联网、人工智能等前沿战略赛道,以硬核技术、..[详细]









