


从“看图说话”到“动手干活”:看看国产多模态模型在生产场景下的真实表现
现在,大家对基础模型能力诉求越来越高了,不再满足文本输入,而是混合输入。
比如一张界面截图、一份业务图表、一页扫描合同、一张发票等,模型不仅要能看懂文件中的内容,还要能把内容变成可执行的步骤、提取结构化的信息或者是给出业务结论。
也就是说对于多模态的理解和执行能力要求变高了,而目前国内支持多模态的几款模型有Step 3.7 Flash、Qwen3.6-flash、MiniMax M3等。
那这几款多模态模型,在生产环境下的实际表现怎么样呢?它们到底能不能用于生产环境?
以前大家都喜欢看评分榜单,说实话,估计很多人对榜单分数都没那么在意,很多模型的公开分数都很亮眼,但真到了具体任务里,就歇菜了。
这里我们也不玩虚的,直接用真实环境的任务来进行横向对比多模态理解和执行能力。
测评说明
为了测试保证公平性,这里我把测评方式和测评标准先摆出来,不偏袒任何一家模型,行就是行,不行就不行,只用事实和数据说话。
这里我们确保在同一个任务场景下,用相同的提示词、相同的配置参数、以及相同的工具或方法,来测试不同模型的执行情况,唯一的变量就是模型。并且这里把每个任务的执行结果和时间、token消耗都一并呈现出来。
最终主要看三个点:
1.质量:一次对话能不能给出可用结果,是否需要反复追问。
2.速度:端到端返回是否足够快,能不能适合 Agent 高频调用。
3.成本:模型单价和token消耗,还看后续要不要人工投入。
因为评价一个模型能不能在生产环境使用,核心就看这三个关键维度。
下面我选择了两个案例,都是目前公司高频使用到多模态模型的场景,一个是在Agent中使用,一个是在业务场景以API方式使用。
场景一:根据流程图还原业务逻辑
在写代码前,前后端会在一起设计整个技术方案,这一步少不了系统架构图或者业务流程图,方案敲定之后才进入编码环节,而现在有多模态的加持,我们完全可以把敲定的流程图给到AI帮我们提取里面方案逻辑,并制定实现计划。
比如我们需要完成微信小程序的登录鉴权,并按照如下流程图的逻辑来实现,这里总共分为10步(数箭头):

先把截图放入项目文件中,然后打开Claude Code,输入如下提示词:

首先是Step 3.7 Flash的输出:

Step3.7-flash给出了参与方、完整流程、核心设计思路,其中识别完整流程为10步,总步数和每一步的逻辑与原始流程图完全吻合,这里质量输出还是杠杠的。它不仅能识别图片中的文案、还能理解图片中的流程逻辑,完整准确无误的表达了流程图的逻辑。
下面是MiniMax M3的输出:

MinMax M3的输出总共也是10个步骤,每步的逻辑均正确。
下面我再看Qwen3.6-flash的输出:
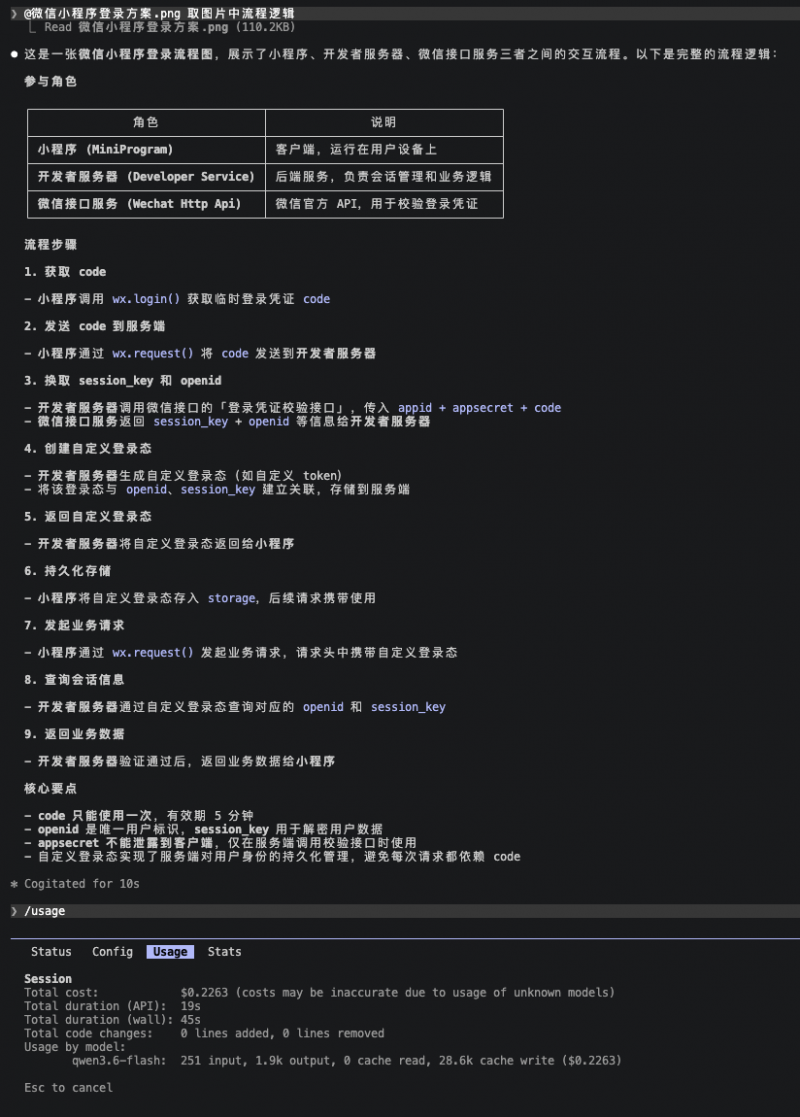
Qwen3.6-flash的输出总共为9个步骤,比参照标准少了一个步骤,它把步骤3、4进行了合并,但是整体逻辑是正确的。
上面每个任务底部都有对应的模型名称、执行时间、Token消耗,这里我把每个模型执行的数据整理到表格中:
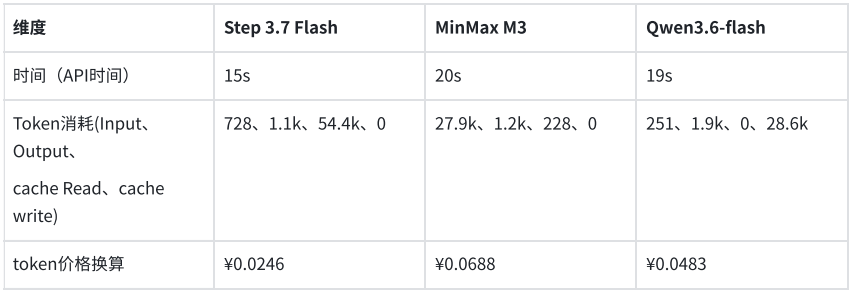
在这个场景下,如果只看输出质量,其实三个模型没有明显的差距。但是根据我们前面定下的标准来看,Step 3.7 Flash的表现更有优势,速度更快、成本更低,而且生成质量稳定。
这个场景非常值得一试,开发中有大量的业务流程图,之前我们还要花不少时间口述给AI,并且容易出错,现在有多模态模型的帮助,确保质量的同时,可以节约很多的时间成本。
下面我们再看一个在业务系统中使用多模态模型的案例。
场景二:利用多模态辅助发票录入系统
我们业务中,有一个录入票据到系统的环节,流程是先拍照上传,人工在根据票据信息依次录入系统表单,操作起来耗时耗力,之前想通过OCR识别来解决,但是识别误差很大,仍然需要人工确认。因为OCR识别有个问题,它是机械的识别信息。
目前我们正在借助多模态模型进行优化,它的优势是不仅能理解信息还能思考。
下面是一张电子发票,任务是让模型识别票据中的信息,并结构化输出关键字段信息,以便自动录入系统,减少人工录入成本。

这里因为是在业务系统中以API的方式调用,因此写了一段测试脚本,其中图片地址和提示词都一致,

其中提示词设置如下:

下面我们还是按照前面的顺序,依次来看每个模型的表现。
我们先把模型切换到Step 3.7 Flash,并运行脚本:

从结果来看,Step 3.7 Flash提取结果完全正确,耗时5.6s,总消耗1409 tokens。
我们在把模型切换到MinMax M3,并运行脚本:

从结果来看,MinMax M3提取结果也完全正确,耗时6.1s,总消耗2216 tokens。
下面我们在将模型切换到千问-3.6-flash,并运行脚本:

从结果可以看出,千问的表现也很稳的,跟前面两个模型的表现差不多,没有出现错误提取的情况,总耗时7.38s,总消耗2008 tokens。
这里在汇总下每个模型执行的情况:

在这个场景中,三者的生成质量仍然没有差异,都能按照要求的JSON结构对票据中的信息准确提取,但是在响应速度和Token的消耗上面,Step 3.7 Flash仍然具有优势一些。
这个识别成本可以说非常低了,一张票据的结构化信息提取成本不到1分钱,并且在这张样例发票上,三者都能正确提取字段。因此,把多模态运用到票据结构化信息提取这个场景下,非常值得一试。
总结
以上这两个案例,一个是在Agent中使用,一个是在业务接口中使用,验证的其实都是同一件事:模型拿到复杂视觉输入后,能不能根据我们的要求把它转成后续可直接使用的结果。
这里我把两个场景下的实测的结果整理到下面这张表里:

整体而言,在两个场景下,三个模型的质量稳定性都很好,没有出现错误提取的情况,但如果放到生产环境里看,质量只是第一关,后面还要看响应速度、调用成本和是否适合高频接入。
综合这几个维度,我个人会更倾向于把 Step 3.7 Flash 放进 Agent 或业务 API 里优先测试。它在两个场景里都保持了比较好的输出质量,同时速度更快、Token 消耗更低,整体更符合“生产可用”的要求。
当然,这并不是说一个模型可以覆盖所有场景,真正上线前,还是要拿自己的业务样本去跑一轮。
好了,以上测评仅代表个人实际测评,大家也可用类似的任务去感受一下Step 3.7 Flash的多模态理解和执行的整体表现。
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
智元彭志辉:当AI走出屏幕,谁在消耗下一个万亿Token?
“未来最大的Token消耗者,将是现实世界里的具身智能体。”对具身智能体拥有如此巨大“胃口”这个结论,是在MWC2026世界移动通信大会上,智元机器人联合创始人、总裁兼CTO彭志辉提出的。之所..[详细]
直播 | 2026工业互联网大会
2026年作为“十五五”规划开局关键之年,我国工业互联网建设迈入规模化落地、全产业链深度渗透新阶段,全国工业互联网已实现所有41个工业大类全覆盖,成为驱动实体经济提质增效的核心数字基..[详细]
MWC26上海观察:从工具变成伙伴,AI加速走向“实用”
2026年6月26日,2026年上海世界移动通信大会(MWC26上海)落下帷幕。作为全球移动通信与数字科技的年度风向标,从本届展会“众智启新”的主题不难发现,AI依然是唯一的主角。[详细]
AI工具赋能新时代:普惠大众还是加剧数字鸿沟?
“人工智能不应只服务于少数精英,也不应止步于普通大众,而是应该平等地照亮每一个生命。”中国移动董事长陈忠岳在6月24日MWC2026世界移动通信大会开幕式上说了此番话,在此之前,他还给与..[详细]
“AI×光纤”突破智算极限,长飞向“全球AI光连接基础设施领导者”跃迁
今年的MWC上海展,无论是在新国际博览中心门口、入场区域,还是展馆通道,更或是长飞的展台,都能清晰地看到“AI×光纤 智启未来”的长飞参展主题。值得注意的是,其中I字在视觉呈现中采用了..[详细]
放下身段的连接,能否重回巅峰
不久前,一位业内人士曾感慨,原本今天是5G的生日,居然忘得一干二净了。这或许就是目前很多连接技术的尴尬处境,不只是被很多人戏称为没啥大用的5G,还有普及速度缓慢的Wi-Fi 7,升级换代的..[详细]









