


昇腾0day支持智谱GLM-5,744B模型单机高效推理
2026年2月12日,智谱AI发布Agentic Engineering时代最好的开源模型GLM-5,从“写代码”到“写工程”的能力进一步演进。在Coding与Agent能力上取得开源SOTA表现,在真实编程场景的使用体验逼近Claude Opus 4.5,更擅长复杂系统工程与长程Agent任务。昇腾一直同步支持智谱GLM系列模型,此次GLM-5模型一经开源发布,昇腾AI基础软硬件即实现0day适配,为该模型的推理部署和训练复现提供全流程支持。
更大基座,更强智能
● 参数规模扩展:从355B(激活32B)扩展至744B(激活40B),预训练数据从23T提升至28.5T,更大规模的预训练算力显著提升了模型的通用智能水平。
● 异步强化学习:构建全新的“Slime”框架,支持更大模型规模及更复杂的强化学习任务,提升强化学习后训练流程效率;提出异步智能体强化学习算法,使模型能够持续从长程交互中学习,充分激发预训练模型的潜力。
● 稀疏注意力机制:首次集成DeepSeek Sparse Attention,在维持长文本效果无损的同时,大幅降低模型部署成本,提升Token Efficiency。
Coding能力:对齐Claude Opus 4.5
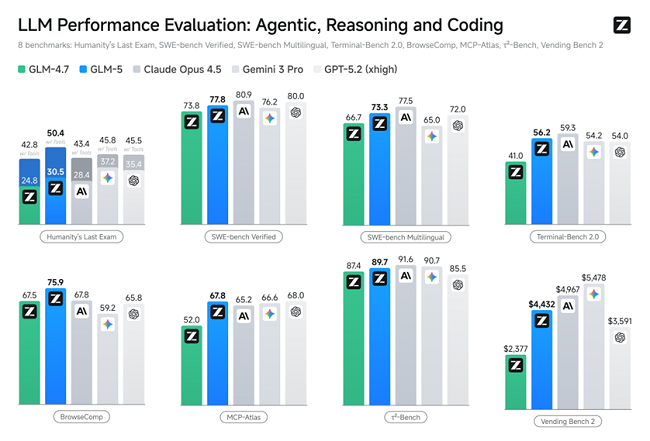
GLM-5在SWE-bench-Verified和Terminal Bench 2.0中,分别获得77.4和55.7的开源模型最高分数,性能超过Gemini 3.0 Pro。
Agent能力:SOTA级长程任务执行
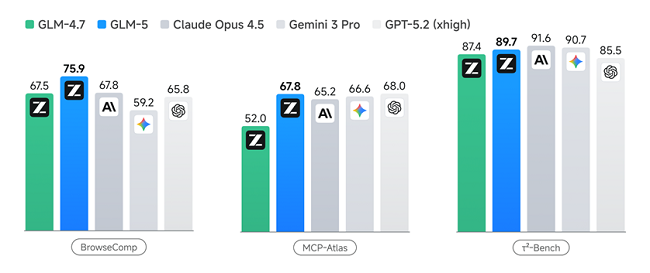
GLM-5在多个Agent测评基准中取得开源第一,在BrowseComp(联网检索与信息理解)、MCP-Atlas(工具调用和多步骤任务执行)和τ²-Bench(复杂多工具场景下的规划和执行)均取得最优表现。
在衡量模型经营能力的Vending Bench 2中,GLM-5获得开源模型中的最佳表现。Vending Bench 2要求模型在一年期内经营一个模拟的自动售货机业务,GLM-5最终账户余额达到4432美元,经营表现接近Claude Opus 4.5,展现了出色的长期规划和资源管理能力。
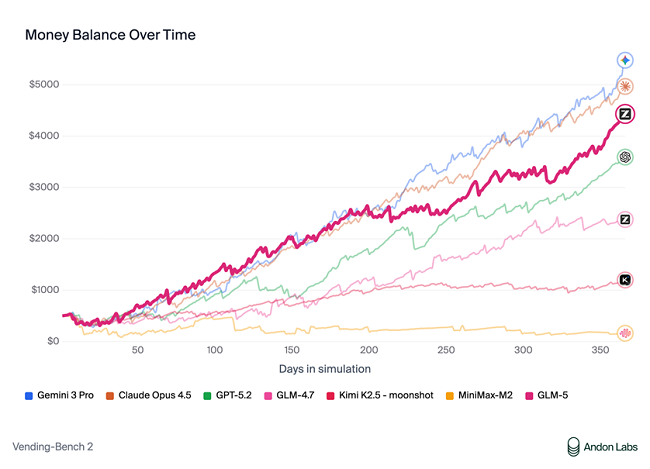
这些能力是Agentic Engineering的核心:模型不仅要能写代码、完成工程,还要能在长程任务中保持目标一致性、进行资源管理、处理多步骤依赖关系,成为真正的Agentic Ready基座模型。
基于昇腾实现GLM-5的混合精度高效推理
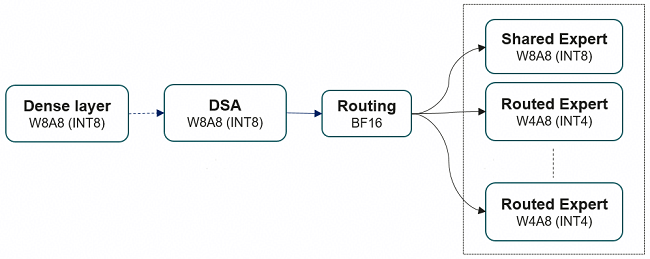
昇腾支持对GLM模型W4A8混合精度量化,744B超大参数模型基于Atlas 800 A3实现单机部署。
GLM-5为78层decoder-only大模型:前3层为Dense FFN,后75层为MoE(路由专家+共享专家),自带一层MTP(Multi-Token Prediction)用于加速解码过程。针对这一模型结构,昇腾对权重文件采用了W4A8量化,极大减少显存占用,加速Decode阶段的执行速度。同时采用了Lightning Indexer、Sparse Flash Attention等高性能融合算子,加速模型端到端的推理执行,并支持业界主流推理引擎vLLM-Ascend、SGLang和xLLM高效部署。
● 权重下载:https://ai.atomgit.com/atomgit-ascend/GLM-5-w4a8
● 推理部署:https://atomgit.com/zai-org/GLM-5-code/blob/main/example/ascend.md
昇腾W4A8量化,极大减少显存占用
采用易扩展的MsModelSlim量化工具,全程轻松量化
1、按模块区分量化比特与算法:例如Attention与MLP主体用W8A8,MoE专家用W4A8;gate等量化敏感层可按需回退,避免过大精度损失。
2、一键即可量化:支持GLM-5量化过程“预处理+子图融合+分层线性量化”的完整流水线,安装后一条命令行即可轻松完成量化:msmodelslim quant --model_path ${model_path} --save_path ${save_path} --model_type GLM-5 --quant_type w4a8 --trust_remote_code True
MsModelSlim提供丰富量化策略,实现快速精度对齐
● 旋转Quarot算法:对权重做Hadamard旋转与LayerNorm融合,降低激活异常值、改善后续量化的数值分布。
● 多种离群值抑制算法:采用Flex_AWQ_SSZ算法和Flex_Smooth_Quant算法混合策略,权重采用SSZ(Smooth Scale Zero)标定,支持缩放因子等超参。
● 线性层量化策略:对单层Linear做W8A8或W4A8,对激活值做per-token粒度量化、对权重做per-channel粒度量化。
高性能融合算子,加速推理执行
1、Lightning Indexer融合Kernel
长序列场景下TopK操作会成为瓶颈,通过引入Lightning Indexer融合算子,包含Score Batchmatmul、ReLU、ReduceSum、TopK等操作,可用TopK计算耗时流水掩盖掉其他操作的耗时,从而提升计算流水收益。
2、Sparse Flash Attention融合Kernel
引入SFA,包含了从完整KVCache里选取TopK相关Token,及计算稀疏Flash Attention操作,可用离散聚合访存耗时掩盖其他操作耗时。
3、MLAPO 融合Kernel
GLM-5在Sparse Flash Attention预处理阶段将query和KV进行降维操作,并且把query降维后的激活值传递给Indexer模块进行稀疏选择处理。近期将会引入MLAPO通过VV融合(多个Vector算子融合)技术,将前处理过程中的13个小算子直接融合成1个超级大算子。除此之外,在MLAPO算子内部,通过Vector和Cube计算单元的并行处理及流水优化,进一步提升算子整体性能。
基于昇腾实现GLM-5的训练复现
GLM-5采用了DeepSeek Sparse Attention(DSA)架构,针对DSA训练场景,昇腾团队设计并实现了昇腾亲和融合算子,从两方面进行优化:一是优化Lightning Indexer Loss计算阶段的内存占用,二是利用昇腾Cube和Vector单元的流水并行来进一步提升计算效率。
训练部署指导:https://modelers.cn/models/MindSpeed/GLM-5
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
盘点2025|光纤光缆:周期性放缓之下,确定性开始凸显
在2025年,光纤光缆厂商们习惯于用“周期性”一词来描述当前的困难,相比于宽带普及、4G升级换代带来的流量需求猛增这一巨大业务增长。可如今在刷着短视频、看着带货的新日常生活常态下,尽..[详细]
盘点2025|人工智能:破局前行、以智启新,同赴人机共生新未来
2025年,人工智能行业迎来技术迭代与价值落地的双重关口。这一年里既延续着近年来的高速增长态势,也迎来从野蛮生长向规范提质的深刻转型。 [详细]
盘点2025|算力行业:量质齐升的进阶之路
在数字经济加速渗透全球经济社会各领域的今天,算力已成为继电力、水资源之后的关键生产要素,是支撑数字中国建设、推动高质量发展的核心基础设施。算力的规模与质量直接决定了数字经济的发..[详细]
盘点2025|芯片:AI依旧是挖潜点,应用进一步多样化
时至2025年年底,人们已经开始渐渐习惯,有事听听AI给出的参考意见。其背后的算力支撑也在逐步加强,像是更先进的制程,以及向更多端侧设备的拓展。另一方面,AI又一石激起千层浪,机遇与需..[详细]
盘点2025 | 从5G到6G:深耕与突破并行,开启智能连接新纪元
2025年,全球通信产业站在了一个关键的历史交汇点。这一年既是“十四五”规划的收官年,5G建设成果全面转化的验收年,也是“十五五”规划启幕,6G布局从技术探索迈向工程落地的奠基之年,更..[详细]
盘点2025|量子信息:三大领域技术持续演进,产业发展未来可期
以量子计算、量子通信和量子精密测量为代表的量子信息技术是挑战人类调控微观世界能力极限的世纪系统工程,是对传统技术体系产生冲击、进行重构的重大颠覆性创新,将引领新一轮科技革命和产..[详细]
盘点2025|2025年智能终端趋势洞察:AI重构体验,超级终端时代加速到来
2025年,全球智能终端行业站在了技术革新与生态重构的十字路口。AI技术的规模化渗透、折叠屏形态的成熟落地、跨设备协同的深度演进,正在重塑终端产品的价值逻辑与市场格局。[详细]
全球人工智能飞速发展,技术、应用、生态协同共振
近日,中国信通院发布的《人工智能产业发展研究报告(2025 年)》(以下简称《报告》)指出,2025 年,全球人工智能飞速发展,技术、应用、生态协同共振,重塑开发范式、改变人机交互模式,催..[详细]
轨道上的两个未来:全球低轨竞赛中的技术、资本与理想
就在中国老百姓喜迎2026马年新春之时,全球航天界传来两个炸裂的消息。2月1日,马斯克旗下的SpaceX传出,已正式向美国联邦通信委员会提交申请,计划部署近100万颗非地球静止轨道卫星;就在三..[详细]
私有AI规模化落地,平台能力让智能不止“聪明一时”
很多企业员工都在过去两年,经历着AI逐步规模化落地所带来的改变。 Cloudera大中华区技术总监刘隶放就在近期的一场技术趋势分享会上,讲述了自己准备这场演讲的过程。以往他需要在笔记软件中..[详细]









