


融合数据库不是“一库打天下”,而是“内核能力重构”
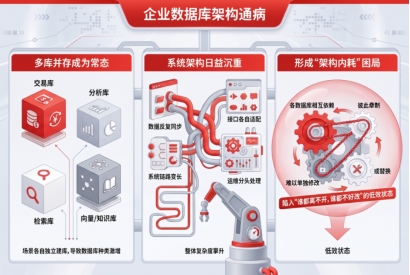
很多企业的数据库架构其实都在走向同一个问题:库越来越多,链路越来越长,系统越来越重。
交易要上一套库,分析要上一套库,检索要上一套库,向量和知识库又是一套。表面看,各类需求都被满足了;但从工程上看,代价也很直接: 数据要反复同步,接口要分别适配,运维要分头处理,最后形成一个谁都离不开、谁都不好改的“多库并存”体系。
这就是今天很多企业正在面对的架构内耗。
所以,讨论“融合数据库”,不能停留在“一库打天下”这种粗糙的理解上。真正的融合,不是拿一个库去替掉世界上所有专用数据库,也不是把几种能力塞进同一个产品包装里。它要解决的,是企业已经被拆散的数据能力,能不能重新回到一个统一底座上。
什么是真正的融合数据库

融合数据库的重点不是新增几个功能点,而是把数据模型、执行引擎、部署架构、开发运维和AI能力重新组织成一个体系。
从技术上看,融合数据库至少有三个判断标准。
第一,不是多组件拼装,而是统一内核。
这是“融合”和“组合”最本质的区别。如果关系、时序、图、向量、分析能力背后仍然是几套独立引擎,那数据同步、事务边界、查询协调、权限治理这些老问题一个都不会少。对用户来说,只是把原来的“多产品采购”,换成了“单产品打包”。
真正的融合型数据库,必须建立在统一内核之上。也就是说,多种数据模型、多类处理能力,不是外挂组件,也不是旁路系统,而是在同一底层架构里原生协同。这一点决定了融合到底是“工程能力”,还是“市场说法”。

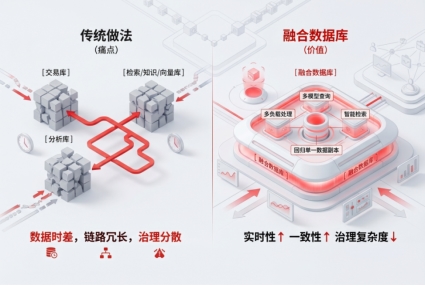
第二,不是多份副本流转,而是单一数据副本上的协同处理。
过去企业最常见的做法,是把交易库的数据抽到分析库,再同步到检索库、知识库或向量库。这样做不是不能用,但问题也很明显:数据有时差,链路会变长,治理会变散。
融合数据库的价值,就在于尽量把这件事往回收。核心业务数据不再在多个系统之间反复搬运,而是尽可能在单一数据副本上完成多模型查询、多负载处理和智能检索。这样做的意义,不只是省几套软件,而是把实时性、一致性和治理复杂度一起拉回来。
第三,不是单点能力堆叠,而是多模型、多负载的原生协同。
今天企业面对的业务,已经不是单一关系模型就能覆盖的。文档、时序、图、向量,都在进入一线业务流程;OLTP、OLAP、HTAP、语义检索、RAG支撑,也不再是完全分开的几条线。
如果数据库只能“分别支持”,那本质上还是各干各的。真正的融合,应该是这些能力能在同一套体系里协同工作。
以多模为例,关键不在于“能不能存文档、向量、图”,而在于能不能统一管理、统一索引、统一查询,必要时还能用一条SQL把多种数据关联起来,实现复杂检索。
以多负载为例,关键不在于“既能做交易也能做分析”,而在于能不能在保证 OLTP 高并发、低时延的同时,支撑 OLAP 的高吞吐分析,并通过负载隔离避免相互争抢资源。否则,所谓 HTAP 很容易退化成“谁忙谁拖慢全场”。
融合数据库需要补齐的关键能力
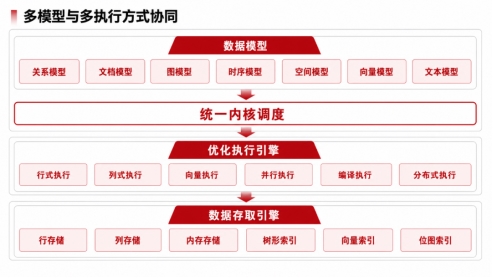
融合的技术内涵,不是把关系、文档、图、向量简单并列,而是让多模型与多执行方式在同一架构内协同。
如果把这个逻辑再往下拆,融合数据库在工程实现上通常还要补齐几件事。
一是语法和生态兼容。企业不可能因为数据库升级就重写系统,所以兼容 Oracle、MySQL、PostgreSQL、SQL Server 等主流生态,本质上不是“锦上添花”,而是决定能不能平滑落地的前提。
二是部署架构统一。单实例、主备、读写分离、共享存储集群、分布式、存算分离、跨中心多活,这些不是不同产品线的问题,而是同一底座对不同场景的适配能力。
三是开发运维一体化。融合如果只停留在数据和执行层,效果还是不完整。开发、迁移、监控、巡检、诊断、调优、自治运维,必须一起收进来,否则能力越多,维护面越大。
四是 AI 与数据库双向融合。这里有两个方向。一个方向是 DB for AI,让数据库更好地支撑向量检索、语义查询、RAG 等智能应用;另一个方向是 AI for DB,让 AI 参与 SQL 生成、异常诊断、性能调优和运维自治。前者决定数据库能不能接住 AI 业务,后者决定数据库自己能不能更高效地运行。
不是能力做加法,而是底座做减法
这也是为什么说,融合数据库的重点不是“多”,而是“通”。语法要通,数据要通,负载要通,架构要通,运维要通,AI 能力也要通。只有这些层面都打通,融合才不是一句口号。
从用户价值看,这套逻辑最后会落到四个结果上:历史应用可以平滑迁移,多种业务场景可以统一承载,多模数据可以统一处理,开发运维可以统一管理。说得更直接一点,就是少几套库、少几条链路、少几轮同步、少几套治理体系。

用户最终感知到的,不是“融合”这个词本身,而是迁移成本、架构复杂度和运维负担是否真正下降。
所以,融合数据库的技术内涵,归根到底不是“能力做加法”,而是“底座做减法”。它不是把数据库做得越来越像一个大杂烩,而是把原本分散、重复、割裂的数据能力重新收拢,变成一个可协同、可治理、可支撑 AI 业务的数据基础设施。
这件事比做一个新功能难得多,因为它改的是底层逻辑,不是表层接口。但数据库下一阶段真正的竞争,也恰恰在这里。谁能先把“多库并存”的内耗降下来,谁才更有机会成为 AI 时代的新底座。
1.本网刊载内容,凡注明来源为“飞象网”和“飞象原创”皆属飞象网版权所有,未经允许禁止转载、摘编及镜像,违者必究。对于经过授权可以转载,请必须保持转载文章、图像、音视频的完整性,并完整标注作者信息和飞象网来源。
2.凡注明“来源:XXXX”的作品,均转载自其它媒体,在于传播更多行业信息,并不代表本网赞同其观点和对其真实性负责。
3.如因作品内容、版权和其它问题,请在相关作品刊发之日起30日内与本网联系,我们将第一时间予以处理。
本站联系电话为86-010-87765777,邮件后缀为cctime.com,冒充本站员工以任何其他联系方式,进行的“内容核实”、“商务联系”等行为,均不能代表本站。本站拥有对此声明的最终解释权。
我国1ms城市算网建设正在进入规模发展关键期
当前,人工智能产业全面进入应用落地关键阶段,大模型训练推理、实时交互、数字孪生等高实时性业务爆发式增长,对算力网络提出了更高要求,1ms城市算网已成为算力基础设施迈向泛在、智能、确..[详细]
超节点+开放生态:昇腾全力备战Token经济
2026年4月,DeepSeek宣布最新旗舰大模型DeepSeek V4已完成与昇腾全系列产品的适配,这个消息在全球引起了轰动,业界普遍认为中国AI推理将逐步摆脱对英伟达等海外算力的依赖,昇腾等国产算力..[详细]
实地探访数智标杆:解锁“十五五”湖北发展新图景
2026年5月17日,世界电信和信息社会日大会在湖北武汉盛大召开。大会期间,飞象网和多家媒体受邀走访了宜昌、孝感、武汉三地的十多个数字基础设施、产业数智化标杆项目,见证了湖北省推进5G/5..[详细]
内存涨价压力大,苹果芯片分级策略变成香饽饽
中低端机型被砍单的消息,在今年初已经传得沸沸扬扬,原因在于伴随着存储价格上涨,中低端机型的涨价幅度可能在300~500元,内存成本开始严重蚕食安卓厂商利润,于是据传两大手机芯片厂商据传..[详细]
十五五启新程:中天科技以文化、ESG与AI擘画远景聚力前行
5月16日,在世界电信日前夕,2026年“媒体走进中天”交流会在江苏南通中天科技集团总部隆重举办。本次活动举办的时代背景,既锚定“十五五”开局之年,布局新质生产力发展的关键节点,也彰显..[详细]
Token套餐落地!不卷流量卷算力,运营商All in词元赛道
国内三大基础电信运营商均已公布面向个人、家庭及政企市场的算力Token套餐。从“流量GB”到“Token计价”,这绝非简单的产品迭代,而是运营商应对 AI 算力爆发、破解传统业务增长瓶颈的战略..[详细]









